Invested
$30–40B
Poured into generative AI by enterprises (estimated).


The only WhatsApp guide you won't find anywhere else.



Most AI pilots never make it to production. This article explains how to tell whether your PoC should be scaled on top of — or rebuilt — and what it actually takes to turn AI experiments into production systems.


Most enterprise AI pilots stall in pilot purgatory — MIT's 2025 GenAI Divide report puts the failure rate at 95%. The way out isn't another pilot; it's a diagnostic decision. Pilots with sound foundations get layered: production capabilities added on top of what already works. Pilots with structural flaws get rebuilt smartly, preserving the use case validation while replacing only the production-critical foundations. Five dimensions tell you which path applies — data integration, latency and cost profile, logic maintainability, tech stack viability, and governance gaps.
The hardest question in enterprise AI right now isn't "should we invest?" — most companies already have. It's "why doesn't our pilot ship?"
In its 2025 State of AI in Business report, MIT's NANDA initiative found that 95% of enterprise generative AI pilots delivered no measurable P&L impact, and only 5% of integrated systems created significant value.The pattern is consistent: pilots impress in demos, then stall on the way to production. Meanwhile, enterprises have poured an estimated $30–40 billion into generative AI, with little to show for it at the enterprise level.
Poured into generative AI by enterprises (estimated).
Of enterprise generative AI pilots delivered no measurable P&L impact.
If your team has built a working proof of concept with Claude or ChatGPT and you're now staring at the gap between "it works in a notebook" and "it serves a thousand users a day," you're in the most common and most expensive place in enterprise AI today. This article is about how to get out of it.
There's a name for this state: pilot purgatory. The project isn't killed and isn't shipped — it just runs quietly while attention moves on. PoCs land there for different reasons and none of them are about the model.
Main reasons why pilots stall:
They're built to demo, not to run. A typical pilot is a notebook, a quick interface, and a hardcoded API key. It uses cleaned, hand-picked data. It runs for one user at a time. None of that translates to production, and the team that built it often doesn't realise it's supposed to.
Ownership disappears after the pilot. Many pilots run out of innovation teams or external AI consultants. Once they wrap, there's no engineering team to take it on, no product owner, and no operating budget. The PoC enters limbo.
Cost surprises hit at scale. The pilot ran on one document. Production runs on a million. Per-call cost matters, latency matters, caching matters. Teams discover this after committing to a launch date.
The data wasn't ready. Pilots often work because someone manually prepared the inputs. Production is a different environment. The model will encounter:
Pipelines, access controls, and freshness checks all need to be built. The data work usually outsizes the model work — and is rarely scoped into the pilot budget.
Workflow misalignment. A lot of pilots operate outside real work. The organisations succeeding with AI redesign workflows; they don't just bolt AI on top. Production AI usually requires:
Without that work, even an accurate model gets ignored by the people it was built to help.
Security, compliance, and governance. In regulated or enterprise environments, this becomes the slowdown that matters most. Typical concerns include:
Legal and security teams often enter the conversation late and stop deployment outright. Organisations that scale successfully do the opposite. They:
The underlying cause why pilots don’t scale is that most AI pilots are designed to answer a different question than production requires. A pilot asks: can this work? Production asks: can this work reliably, securely, at scale, and within our operating model — every day, for every user, with predictable cost? Those are not the same question, and a system optimised to answer the first will rarely satisfy the second without modification.
Once you have a working PoC, you face a fork. Either you build production on top of what you already have, or you treat the PoC as a learning exercise and start over with a system designed for production from day one.
Getting this call right is the most consequential decision in the journey from AI pilot to production. Layering on top of a weak foundation creates technical debt that surfaces six months later — at exactly the wrong moment. Rebuilding when you didn't need to — wastes three to six months and lets the window close.
| # | Dimension | Salvageable → Layer | Mismatched → Rebuild |
|---|---|---|---|
| 1 | Data integration | Reads from production systems of record (ERP, CRM, warehouse) | Reads from hand-curated extracts or static datasets |
| 2 | Latency & cost profile | Within an order of magnitude of production targets | Multiple orders of magnitude off (e.g. 4–6 min response when seconds are required) |
| 3 | Logic maintainability | Modular prompts, structured orchestration, clear business rules | Forty-page prompt, one-off scripts, brittle logic |
| 4 | Tech stack viability | Built on platforms the production org can operate and secure | One-person developer setup or tools the org can’t support |
| 5 | Governance gaps | Security, audit, identity can be added without redesign | Adding controls would require pulling the architecture apart |
Decision rule: If most rows fall in the left column, layer on top — keep the pilot, add the production-critical capabilities on top of it. If two or more rows fall in the right column, rebuild — but smartly. The conceptual work the pilot did is still valuable. The architecture isn't.
The instinct to layer is strong, because rebuilding feels like throwing away work. It isn't. A pilot's job is to validate the business case and surface the unknowns. If it did that, it succeeded — even if none of its code survives.
Share what you've built — a notebook, a Claude project, a working prototype — and a BotsCrew architect will walk through the five dimensions with you and flag the structural risks before they surface in production.
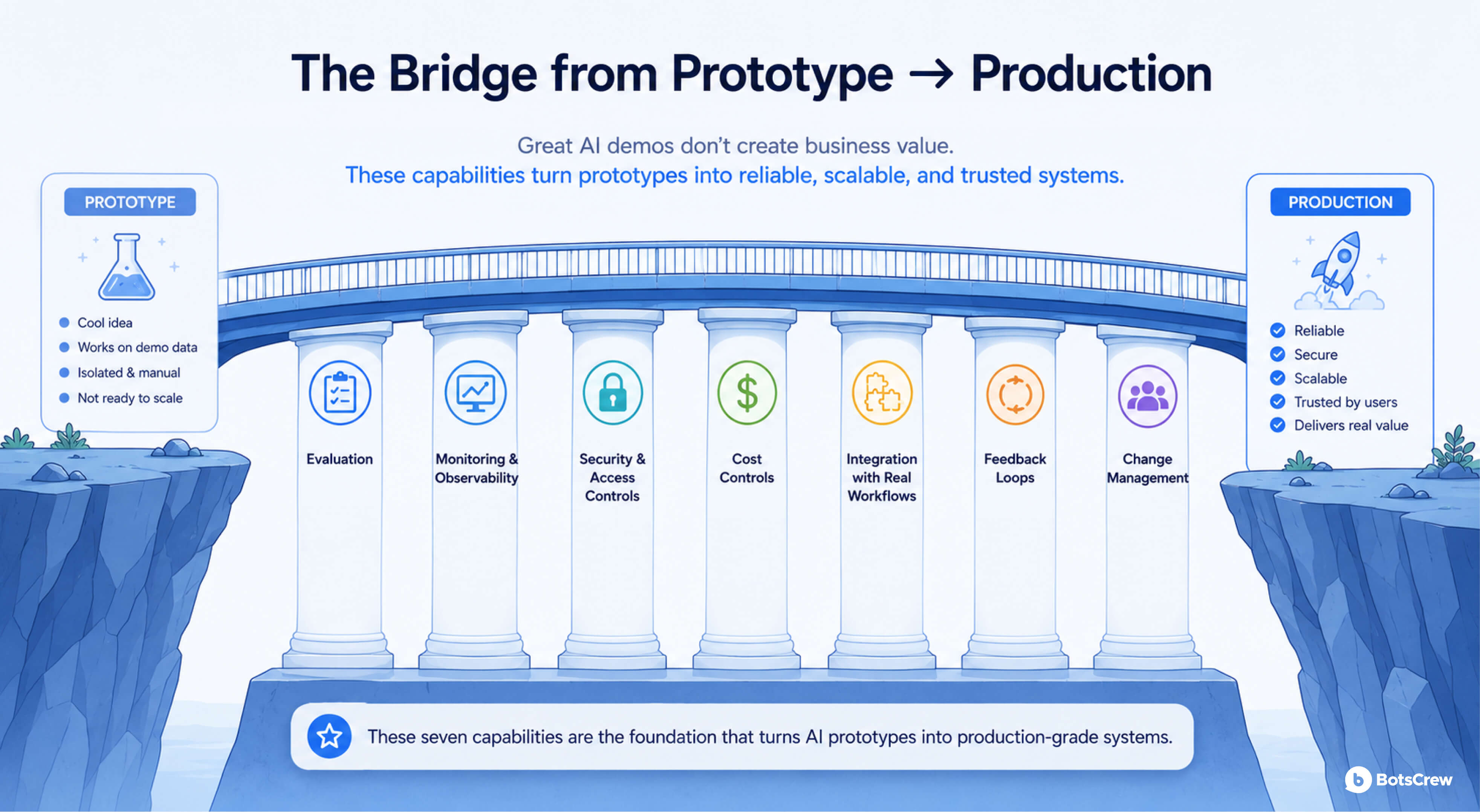
Request a pilot reviewEvaluation. A repeatable way to measure whether the system is getting better or worse over time, on cases that matter to the business. Without AI metrics & KPIs, you can't safely change prompts, swap models, or extend the system.
Monitoring and observability. Logs of what users asked, what the system answered, what it cost, and what failed. You can't operate what you can't see.
Security and access controls. Who can use the system, what data it can read, where outputs go, and how prompts and logs are stored. For regulated industries, like financial services, healthcare, legal — this is the deal-breaker.
Cost controls. Per-call cost ceilings, alerting on usage spikes, and a clear unit economic story per transaction. AI projects with no cost discipline routinely overrun by three to five times.
Integration with real workflows. The PoC asked users to come to a separate app. Production has to live inside CRM, the help desk, the document review tool, or the inbox — wherever the work already happens. The MIT report is blunt here: tools that don't fit existing workflows get abandoned, even when they're technically better than what they replace.
Feedback loops. A way for users to flag bad outputs and for the system to learn from those signals. Without this, the system can't improve, and trust erodes.
Change management. Training, communication, and a clear story for the people whose jobs are about to change. AI projects fail more often on adoption than on technology.
A working enterprise AI deployment strategy moves through five stages.
1. Define production criteria before you scale. Before touching the PoC, write down what production looks like. Latency budget, cost per transaction, accuracy threshold, compliance requirements, integrations, etc. This becomes the definition of done and prevents the project from drifting indefinitely.
2. Audit the PoC against those criteria. Walk through the seven production requirements above. Be honest about gaps. This audit produces the layer-vs-rebuild call and a realistic timeline. If the audit takes longer than two weeks, you're already learning that the PoC was less complete than it looked.
3. Build the production scaffold. Whether layering or rebuilding, the next phase is the unglamorous one: evaluation harness, monitoring, security, cost controls. Most teams want to skip this and ship features. The teams that do skip it ship something fragile and pay for it within a quarter.
4. Run in shadow mode, then parallel. Before letting the AI make decisions that reach customers or alter records, run it alongside the existing process. Compare its outputs to the human baseline. This builds trust, exposes failure modes, and creates the evaluation data you'll need for every future change.
5. Roll out gradually with clear ownership. One team, then one business unit, then organisation-wide. Each step should have a named owner, a measurable success criterion, and a defined rollback. Enterprise AI adoption isn't a launch event; it's a sequence of expansions, each validated by the last.
The companies in MIT's successful 5% don't have better models. They have better operating discipline around the model. The model is one component of a system; the system is what creates business value.
The challenge of moving AI from pilot to production rarely looks abstract once you see it in a real operation. Consider S&B Filters, a U.S. manufacturer of high-performance air filters with more than 700 employees, running its order management, internal workflows, and customer data on NetSuite. As inquiry volume scaled with the business, the support team came under increasing pressure to handle order-status, delivery, and product questions across Shopify, phone, and email.
S&B's CEO, Berry Carter, is the kind of leader who builds before he buys. Rather than wait for a vendor pitch, he wired Claude's Model Context Protocol connector to NetSuite himself, wrote his own prompts, and stood up an internal AI assistant for order status. For a CEO-built prototype, it worked. It proved the use case. It showed the team what was possible.
Then the diagnostic problems surfaced — and they were structural. Response times reached four to six minutes, unusable in a live customer conversation. The system relied on a forty-page prompt that was difficult to maintain and inconsistent in output. Real-world inputs varied wildly: PO numbers arrived as "PO-1234," "1234," and other formats across channels. The prototype behaved as an internal experiment, not a customer-grade system.
Applied to the diagnostic, this was not a case for layering. The architecture, prompt design, and latency profile were all mismatched to the production use case. Hardening in place would not have closed the gap. But neither was it a case for starting over — the use case had been validated, the NetSuite integration thesis was right, and the business value was clear.
When BotsCrew took on the rebuild, the discipline was to preserve what mattered and replace what didn't. The conceptual validation, the integration approach with NetSuite, and the use case prioritisation were all kept. What was rebuilt were the production-critical layers: a stable orchestration architecture, an input normalisation layer that handles messy PO numbers across channels, a dynamic knowledge layer connected to OneDrive so the client can update product content without redeployment, and latency-optimised retrieval paths against NetSuite. A single architecture now serves both an internal AI assistant for support agents and a customer-facing assistant on the website.
Within four weeks, V2 was live for internal support agents. Order lookups that had taken minutes inside NetSuite resolved in seconds — a 98 percent reduction in first response time. Today, the AI layer handles between 30 and 50 percent of customer inquiries fully autonomously, with projected annual cost savings of $94,000 to $141,000 and a Year 1 ROI of 134 to 251 percent.
The lesson is not that rebuilds are good or bad. It is that a rebuild done with a clear view of what to preserve — and what to replace — takes weeks, not quarters, and pays back inside the first year.
Want the full picture? The complete S&B Filters case study covers the architecture decisions, what we preserved from the CEO's prototype, how the input normalisation layer handles messy PO numbers across channels, and the four-week build timeline in detail.
Read the full S&B Filters case studyHow do you move AI from pilot to production? Diagnose the pilot along five dimensions — data integration, latency and cost profile, logic maintainability, tech stack viability, and governance gaps. Sound pilots get layered into production by adding lifecycle management, governance, optimisation, and observability. Pilots with structural flaws get rebuilt smartly: preserve the use case validation and integration knowledge, replace the architecture, stack, and unmaintainable logic.
What is pilot purgatory in AI projects? Pilot purgatory is the state where a working AI proof of concept never makes it into production. Roughly 80 percent of enterprise AI projects stall here (RAND Corporation, 2024), typically because the pilot was framed to answer "can this work?" rather than "can this work reliably at scale?"
Should I rebuild my AI pilot or layer on top of it? Layer if the data integration is sound, the latency is within an order of magnitude of production targets, the logic is maintainable, and the tech stack is one the production organisation can support. Rebuild — smartly — if two or more of those fundamentals are mismatched.
How long does a smart AI pilot-to-production rebuild take? Typically four to eight weeks, because the most expensive work — proving the use case — has already been done. A full ground-up rebuild that discards the pilot's learning usually takes six to twelve months.
What's the cost of moving AI from pilot to production? The layer path usually costs a fraction of the original pilot, because the model logic, integration patterns, and data transformations stay intact and only operational layers are added. A smart rebuild costs more, but documented examples — including S&B Filters' production AI deployment — have delivered 134–251% ROI in Year 1, with annual cost savings between $94,000 and $141,000.
What's the difference between an AI proof of concept and a production AI system? A proof of concept answers "can this work?" — usually in a controlled environment, with curated data and limited scale. A production AI system answers "can this work reliably, securely, at scale, every day, for every user, with predictable cost?" Closing that gap is what the layer-or-rebuild diagnostic is for.
BotsCrew works with mid-sized and enterprise teams on exactly this transition — from a working pilot to a production AI system, in weeks rather than quarters. A 30-minute call is usually enough to scope the gap.
Schedule a strategy call

