




How to Train an LLM Using Fine-Tuning? Best Practices for Businesses
Large Language Models (LLMs) excel at tackling everyday tasks right out of the box. But what happens when the challenge demands expertise beyond their standard grasp? That is where fine-tuning comes into play — transforming the model through tailored training to meet your specific needs. How to train an LLM on your own data using the best practices?


Large Language Models have transformed AI and machine learning, bringing unparalleled capabilities to understanding, generating, and interacting with human language. However, despite their power, training LLMs from scratch is both time-intensive and costly. This is where fine-tuning comes into the game — adapting these advanced models to excel in specific domains or tasks by leveraging unique datasets.
In this article, we provide a bird's-eye overview of LLMs as well as explore how fine-tuning transforms them from generic predictive engines into highly specialized assets tailored to an organization's needs and how to train an LLM for a company's success.
Understanding How Pre-trained Language Models Work
Large Language Models (LLMs) are typically trained through a multi-stage process, beginning with pre-training on massive collections of text data. This foundational step equips LLMs with an understanding of the core rules that shape word usage and structure in natural language (NL), allowing them to excel not only at interpreting natural language but also at crafting human-like text that seamlessly responds to the input they are given.
LLM input and output
Chances are, you are familiar with some of the big names in the world of LLMs — like OpenAI's GPT-4, Anthropic's Claude, and Meta's Llama-2. These flagship models and their development teams often dominate the spotlight.

Oleh Pylypchak, Chief Technology Officer and Co-Founder at BotsCrew
"The most popular commercial LLMs are multi-purpose systems. They are not designed with a specific focus, like legal or financial models — you can try using them for virtually any task.
These models aren't trained for a particular task but rather on a vast amount of general information, which allows them to handle a wide range of activities. This marks a revolutionary shift with the advent of LLMs, where models evolved from being single-purpose to multi-purpose, thanks to pre-training."
However, the field is constantly evolving, and alongside these giants, more specialized LLMs are emerging — models designed for niche, industry-specific tasks.
Take SciBERT, a BERT variant fine-tuned on scientific literature, or OpenAI Codex, an LLM crafted to translate natural language instructions into code. These lesser-known yet highly specialized pre-trained models showcase the incredible diversity of applications LLMs can serve.

However, pre-training is an expensive process, often costing hundreds of thousands of dollars in computational resources. In contrast, fine-tuning an LLM is significantly more affordable.
With the widespread availability and even free access (including for commercial use) to pre-trained LLMs, companies have the opportunity to unlock the potential for creating a wide array of powerful, tailored applications by fine-tuning these models for specific tasks.
What is LLM Fine-tuning, and Why is it Important?
Most LLMs today excel at delivering strong overall performance but often stumble when tackling specific, task-oriented challenges. So, what is LLM fine-tuning? Fine-tuning customizes a model to excel at particular tasks, enhancing its effectiveness and adaptability for real-world applications.
This process is crucial for adapting a pre-trained model to meet the unique business-specific needs, demands of a particular domain or task, domain-specific language, and more.
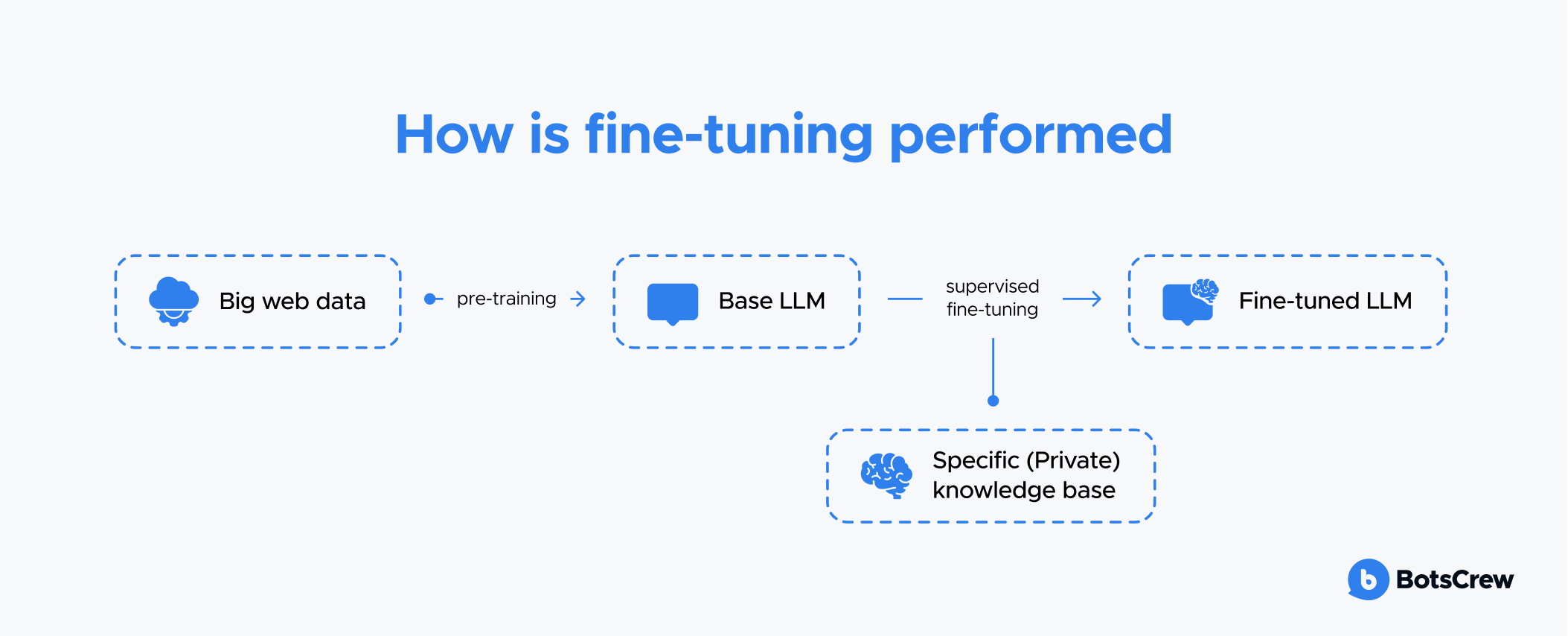
Pre-training an LLM is like making the base of a recipe — a solid starting point. Fine-tuning is like adding spices, giving it a unique flavor, and making it just right for specific needs.
Imagine a healthcare organization wanting to use GPT-4 or another model to help doctors create patient reports from textual notes. While GPT-3 is great at understanding and generating general text, it might not be perfectly suited for the complex medical language and specific healthcare terms needed in this case.
To improve its ability to handle this specialized task, the organization fine-tunes GPT-3 on a dataset filled with medical reports and patient notes. This process allows the model to better understand medical terminology, the subtleties of clinical language, and the common structure of reports. After fine-tuning, GPT-3 becomes much more adept at helping doctors generate accurate and coherent patient reports tailored to the medical field.
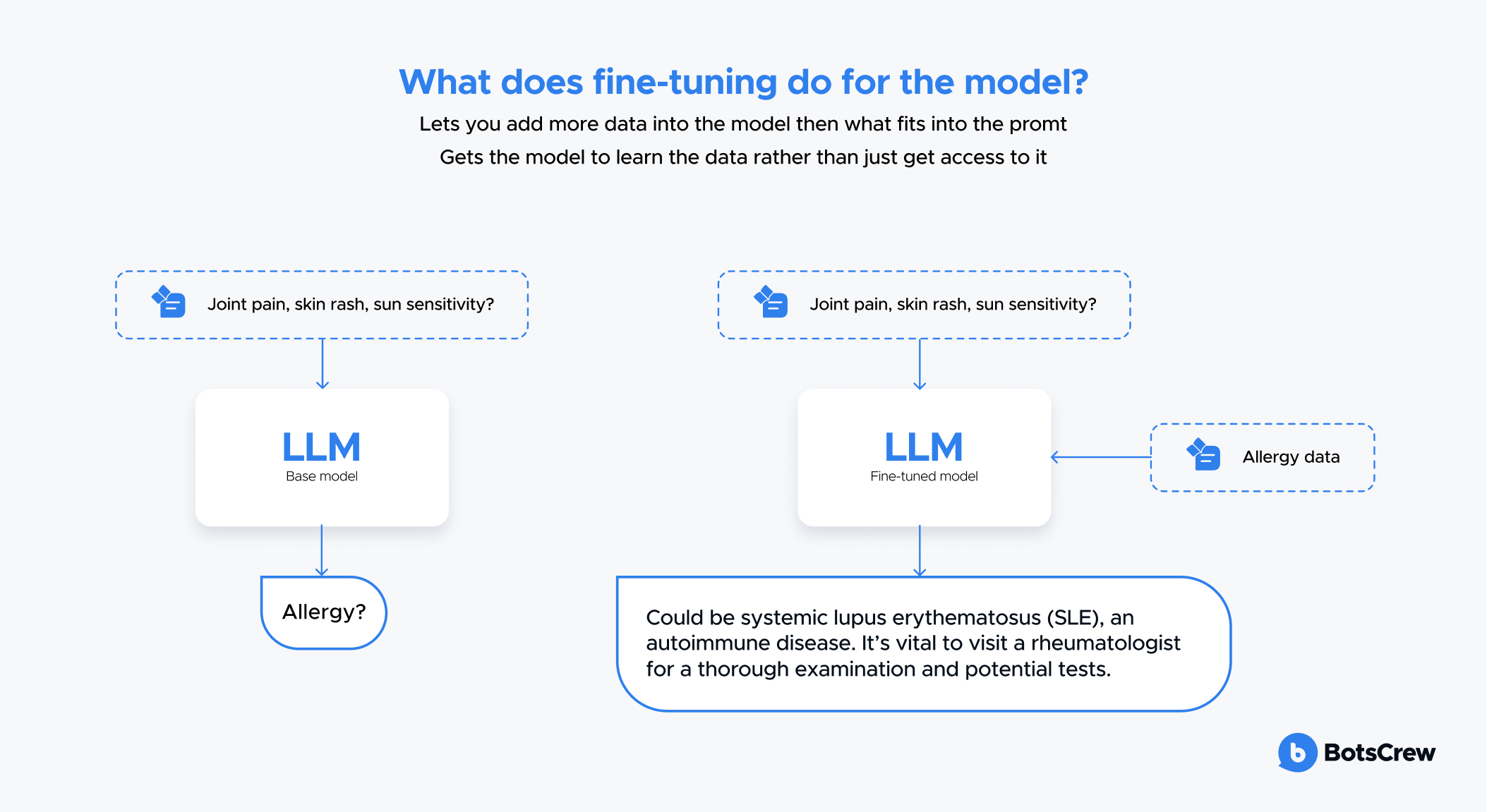
Let's dive into an example to illustrate this more clearly. Imagine asking a pre-trained model, "Why is the sky blue?" it might simply respond, "Because of the way the atmosphere scatters sunlight." While this is a correct and straightforward answer, it might not be detailed enough for a chatbot on a science educational platform, where users expect more in-depth explanations. This is where supervised fine-tuning comes in.
After fine-tuning, the model can offer a more thorough and contextually appropriate response. So, when asked, "Why is the sky blue?" it might reply with something like this:
"The sky appears blue due to a phenomenon known as Rayleigh scattering. Sunlight, which is made up of different colors, travels through Earth's atmosphere, where it interacts with gases and particles. Blue light has a shorter wavelength compared to other colors, and it gets scattered more widely. This scattering causes the direct sunlight to appear white, but it also gives the sky its characteristic blue hue."
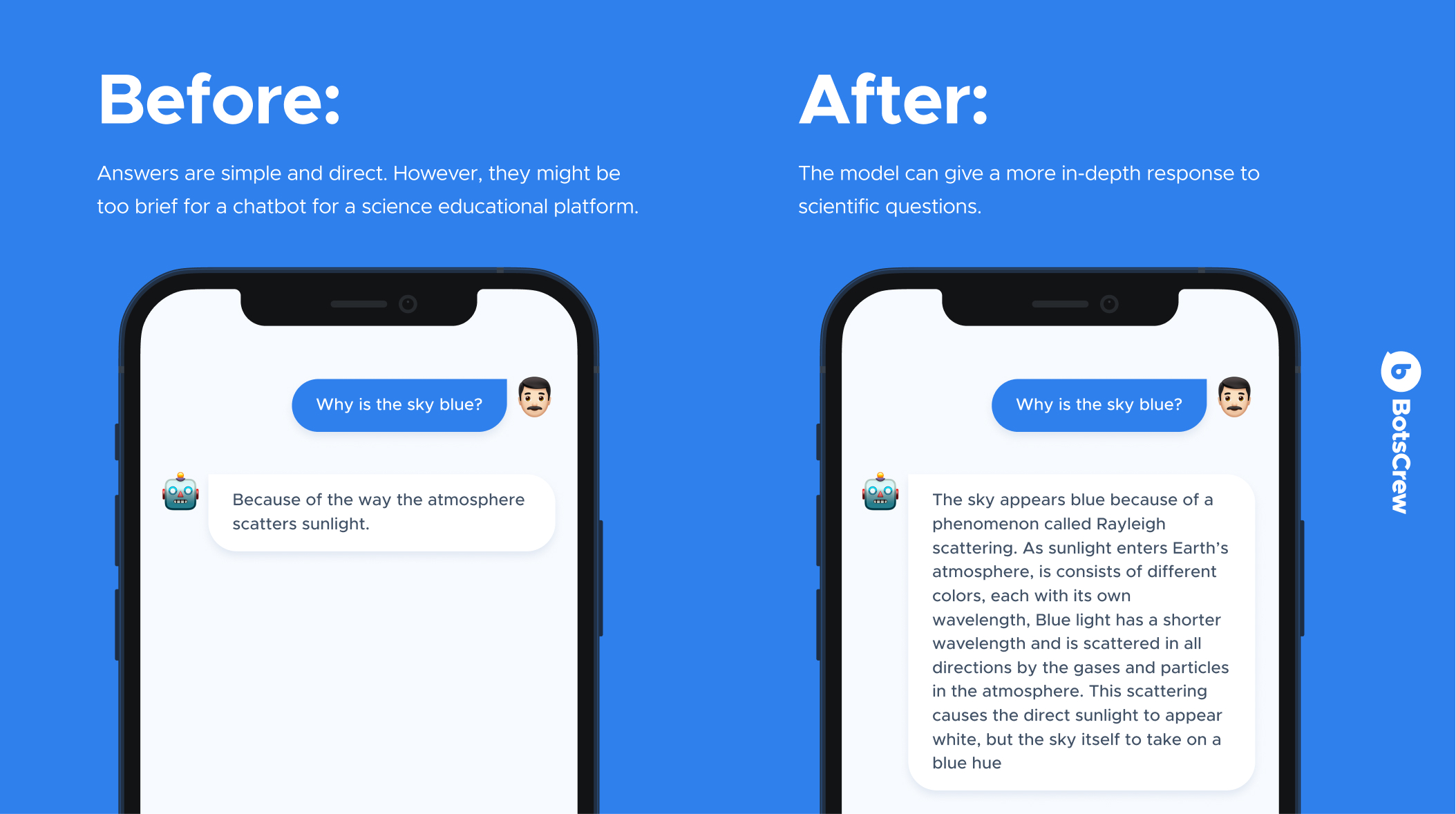
This fine-tuned answer is not only more detailed but also perfectly suited for a science educational platform, providing users with a richer, more informative explanation.
Why Fine-Tuning Matters for Businesses
Why fine-tuning your LLM could be a game-changer for your business:
#1. Tailored to your business needs. LLMs are trained on massive datasets, but they do not always capture the specific language, terminology, or industry context that matters to your business. For instance, a general LLM might not fully understand medical terminology or legal jargon. Fine-tuning allows the model to learn from your domain-specific data, like medical records or legal documents, making it much more adept at generating content that's relevant and precise.
#2. Boosting accuracy. In high-stakes environments, such as finance or legal sectors, even small errors can lead to costly mistakes. Fine-tuning an LLM with your specific data improves its accuracy by aligning its output with your business expectations. For instance, if you run a financial services firm, fine-tuning can help the model generate accurate financial reports or risk assessments by training it on past case studies or historical data specific to your company.
At BotsCrew, we specialize in fine-tuning LLMs for seamless integration into your business. Our team of AI experts has extensive experience customizing and adapting models to your unique use cases, from enhancing customer service to improving decision-making in complex industries like healthcare and finance. Ready to see how LLMs can transform your operations? Book a call with one of our experts today!
#3. Creating personalized experiences. If you use an LLM to interact with customers, like through a chatbot or AI virtual assistant, fine-tuning helps align the model's responses with your brand’s personality.
#4. Handling unique challenges. Every business faces rare but critical scenarios that a general LLM might struggle to address. For instance, in industries like customer support, rare customer queries might involve niche products or services; fine-tuning ensures the model can address these effectively without falling back on generic responses.
#5. Enhanced privacy and security. When you fine-tune an LLM on your private, domain-specific data, you gain better control over how sensitive information is used.
Unlike relying on generic cloud-based models that might process data externally, fine-tuning allows you to deploy the model locally or in a secure environment, minimizing the risk of data breaches or leaks. For instance, a healthcare organization can fine-tune a model on patient data within its own infrastructure, ensuring compliance with privacy regulations like HIPAA while maintaining full control over sensitive information.
In industries such as finance, where precise data management and reporting are crucial, utilizing strong financial reporting tools can drastically improve decision-making and risk assessment. Companies adopting these robust platforms are better equipped to tailor their operations, ensuring they capture the nuances of financial intricacies within ongoing operational models.

When to Use Fine-Tuning
Fine-tuning LLMs is not something to rush into. It requires a careful investment of time, effort, and resources to achieve the best results. Before diving into fine-tuning, we recommend exploring other strategies like prompt engineering, prompt chaining (breaking down complex tasks into smaller steps), and function calling. That is why:
- Many tasks that may seem beyond the model's capabilities at first can yield excellent results with the right prompts. Often, fine-tuning is not necessary when creative and iterative prompt design can solve the issue.
- Refining prompts or chaining tasks allows for quicker experimentation and immediate feedback, unlike fine-tuning, which involves gathering datasets, running training jobs, and waiting for results.
- Even if fine-tuning is ultimately needed, the effort spent on prompt engineering is not wasted. In fact, well-crafted prompts can enhance fine-tuning results, as they provide strong foundations for the training data or can be combined with techniques like prompt chaining and tool usage to maximize performance.
Oleh Pylypchak, Chief Technology Officer and Co-Founder at BotsCrew
"To perform fine-tuning, you need clean data that accurately represents the desired task you want the model to learn. Such data is rarely readily available; it often needs to be collected and cleaned manually, which requires considerable effort. However, if you have access to this quality data, fine-tuning can become a highly effective tool for further training the model."
By starting with prompt optimization and only moving to fine-tuning when truly necessary, you can maximize the efficiency and effectiveness of your LLM applications.
Oleh Pylypchak, Chief Technology Officer and Co-Founder at BotsCrew
"Once, we applied fine-tuning while building a system designed to generate reports — patient conclusions — based on user input for a radiologist. Why did we choose fine-tuning in this case? The company that approached us specialized in software for creating and managing these reports. They had a substantial amount of high-quality data readily available, which could be used quickly, efficiently, and cost-effectively to fine-tune the model for this specific use case."
Fine-Tuning vs Prompt Engineering: What's the Difference?
Fine-tuning and prompt engineering are both approaches to optimize the use of machine learning models, but they differ significantly in methodology, effort, and use cases.
Fine-tuning alters the model itself, while prompt engineering optimizes how you interact with it. Another difference is, that fine-tuning requires more resources and expertise, while prompt engineering is lightweight and fast. Fine-tuning is better for highly specialized tasks; prompt engineering is better for general or adaptable use.
Here is a more detailed breakdown of the differences:
Fine-tuning vs Prompt Engineering
Fine-tuning involves training a pre-existing model on a specific dataset to adapt it for a particular task or domain. This modifies the model's weights and behavior.
Key Features:
✅ Model Training: Requires additional computational resources and a labeled dataset.
✅ Customization: Adjusts the model's internal parameters to better handle domain-specific tasks.
✅ Granularity: Provides deeper, task-specific optimization.
When to use:
- Highly Specialized Tasks. If your use case requires domain-specific knowledge or expertise (e.g., legal, medical, or technical jargon) that a general model may not handle well.
- For tasks where you need consistent, repeatable outputs across a large number of interactions.
- Custom Outputs or Behavior. When the default behavior of the model does not align with your requirements, and prompting alone can't achieve the needed specificity.
- Complex or Multi-Step Logic. For workflows requiring intricate, domain-specific reasoning or output formatting that a general model doesn’t support well.
Advantages:
🙂 Achieves highly specialized results.
🙂 Ideal for cases where default model behavior isn’t sufficient.
Disadvantages:
☹️ Time and resource-intensive.
☹️ Requires technical expertise in machine learning (ML).
Prompt engineering is the art of crafting effective input prompts to elicit the desired output from a pre-trained model without altering its underlying parameters.
Key Features:
✅ No Training: Relies solely on the existing capabilities of the model.
✅ Iterative Tuning: Involves experimenting with phrasing, structure, or context in the input to achieve optimal results.
✅ Flexibility: Works with any task within the model's capabilities without further training.
When to use:
- General Tasks. For common use cases that don’t require deep domain adaptation.
- Low Resource Availability. If you lack labeled datasets, time, or computational power for fine-tuning.
- Quick Prototyping. When you need to rapidly test ideas or solutions without committing resources to training a model.
- Flexible Use Cases. When the task requirements might evolve, and you want to avoid retraining for every small change.
- Budget Constraints. Prompt engineering is a cost-effective way to leverage powerful models without incurring training costs.
Advantages:
🙂 Quick and cost-effective.
🙂 Requires no specialized infrastructure or datasets.
Disadvantages:
☹️ Limited by the pre-trained model’s capabilities.
☹️ May not achieve the same level of precision as fine-tuning for complex tasks.

How to Train an LLM? Best Practices for Fine-Tuning Success
Fine-tuning a model isn't just about feeding it data — it is about doing so thoughtfully to unlock its full potential. Here are some tried-and-true practices how to train an LLM on your own data and to help you get the most out of your fine-tuning efforts:
Prioritize Data Quality and Quantity
The old adage holds true: "Garbage In, Garbage Out." Your dataset is the foundation of the model's performance, so:
- Clean and relevant data is non-negotiable. Ensure examples are accurate, clear, and directly applicable to the task.
- Size matters — but balance it with quality. A smaller, well-curated dataset often outperforms a larger, messy one.
Think of your data as the recipe for success. If it's off, so is the result.
Tune Hyperparameters with Precision
When you think of how to fine-tune LLM on custom data, the process itself requires experimentation to hit the sweet spot. Key parameters to adjust include:
- Learning rate. Determines how fast the model adapts.
- Batch size. Impacts computational efficiency and learning stability.
- Number of training epochs. Influences the depth of learning without risking overfitting.
Fine-tuning is an iterative process, so do not rush it. Precision and patience are your allies in crafting a model that generalizes well to unseen data.
Evaluate the Progress Regularly
Monitoring progress during training is essential to keep your model on track. Regularly evaluate performance using a separate validation dataset to spot early signs of overfitting. Measure how effectively the model handles the desired task. Make timely adjustments to improve outcomes. Last but not least, frequent feedback loops ensure your model is always moving in the right direction.
Refine the Dataset Through Iteration
When the model doesn't meet expectations, revisit your data:
- What is missing? Add examples that target weak areas.
- Is there bias? If some responses are overrepresented (e.g., excessive refusals), rebalance the dataset to reflect desired behaviors.
- Are there errors? Check for flaws in logic or style in your training examples — models tend to mimic the issues they see.
- Is the information complete? Make sure examples include all the context needed for accurate responses.
For instance, if your model "hallucinates" compliments, it may have been trained on examples with traits invented in the response. Refine it accordingly.
Scale Data Smartly
Once the quality is nailed down, consider increasing the dataset size. Expanding your data helps the model learn subtleties, especially for edge cases. To gauge the impact:
- Fine-tune your current dataset.
- Fine-tune on half that dataset.
- Compare results to estimate the quality boost from adding more data.
Challenges and Limitations of Fine-Tuning
Fine-tuning can be a powerful tool for customizing LLMs, but it comes with its own set of challenges and potential drawbacks that must be considered:
Costs and Resources
Fine-tuning large language models involves additional costs, including:
✅ Training Expenses: the computing resources needed to execute the fine-tuning process, which can be quite substantial for large models.
✅ Hosting Costs: storing and deploying custom fine-tuned models often requires dedicated infrastructure.
These costs can escalate depending on the size and complexity of the model and the frequency of updates needed.
Input/Output Formatting
The way you structure your training data — input prompts and expected outputs — can significantly influence the model's performance. Poorly formatted data may result in suboptimal or inconsistent outputs, so this step requires careful planning to align with the desired use case.
Maintenance and Updates
Fine-tuning is not a one-and-done process. Models often require:
✅ Periodic Retraining: to adapt to new data or updates in the target domain.
✅ Recalibration: when an updated base model becomes available, necessitating fine-tuning from scratch.
This cycle of monitoring, updating, and re-fine-tuning can add to long-term resource demands.
Experimentation and Hyperparameter Tuning
Achieving optimal performance often involves a lengthy process of trial and error. Hyperparameters like learning rate, batch size, and regularization settings must be carefully adjusted through extensive experimentation. This repetitive task requires significant expertise and time investment.
Oleh Pylypchak, Chief Technology Officer and Co-Founder at BotsCrew
"Keep in mind that fine-tuning as a process for training LLMs is very specific and quite challenging to implement. This complexity does not stem from the technical aspects, but from the quality of data and the specific datasets required for fine-tuning. In fact, it's not usually the first solution companies turn to when working with LLMs.
We typically begin by fine-tuning LLMs with prompt engineering and assess the quality of task performance required for the project. If we are unable to achieve the desired results through various prompt engineering techniques, then we consider moving towards fine-tuning."
Measuring the Success of Fine-Tuned LLMs
Once deployed, fine-tuned LLMs need vigilant oversight to ensure they deliver consistent performance. Real-time monitoring is key — requiring robust infrastructure to track metrics like model outputs, latency, and usage patterns continuously. This allows for the swift detection of issues such as latency surges or unexpected behaviors in predictions.
But monitoring alone isn't enough. Maintaining a model's relevance requires continuous evaluation. This includes strategies like A/B testing or shadow deployments (runs a new app version alongside the live one, mirroring real user requests to test performance in a real-world scenario), which let you trial updates and improvements without affecting the production environment.
Additionally, regularly testing the model with refreshed data sets ensures it adapts to shifts in data patterns and user behaviour, keeping its output both accurate and reliable over time.
By combining real-time monitoring with ongoing evaluation, you create a feedback loop that ensures your fine-tuned LLM performs at its best, long after it goes live.
Oleh Pylypchak, Chief Technology Officer and Co-Founder at BotsCrew
"We think of fine-tuning as one of many potential tools or approaches to address a client's specific problem or request. Our process involves evaluating various options and selecting the one that offers the best balance of quality, speed, effort, and cost.
If we determine that fine-tuning is the optimal choice, even in cases where the client lacks sufficient high-quality data, we start by working on the data — preparing, cleaning, and testing it. We then carry out the fine-tuning, carefully assessing whether it delivers the desired quality and ensuring the client is satisfied with the results."
Feel unsure whether fine-tuning is a good match for your project? Let us lend a helping hand! Share your data, use case, and goals, and we’ll cut through the noise to recommend the best fit for your business.


