Transforming AI Unstructured Data into Enterprise Value (+ ROI Quiz)
90% of your company's data can't be touched by your analytics stack. It lives in PDFs, emails, meeting transcripts, support tickets, and scanned contracts — invisible to dashboards, inaccessible to decision-makers. Discover how the most forward-thinking enterprises are finally reading AI unstructured data.


Imagine a surgeon who can only look at a patient's X-rays but is not allowed to read the clinical notes, the consultation transcripts, or the discharge summaries from the last three admissions. She would have a partial picture at best, and a dangerous one at worst.
That is precisely the position most enterprises put their leadership teams in every single day. Executives make billion-dollar decisions grounded in structured data: ERP figures, CRM totals, neatly formatted spreadsheets. However, the friction in customer relationships, the recurring failure patterns in operations, or the competitive intelligence buried in contracts are encoded in text, documents, and voice.
And almost none of it is being read systematically, because until very recently, machines couldn't read it either. Explore what it takes to unlock that 90% of AI unstructured data and how to go from document chaos to measurable business outcomes.
Gartner
0%
of all new enterprise data generated today is unstructured — text, documents, audio, images.
Harvard Business Review
0%
of companies admit they lack the data infrastructure needed to adopt AI effectively.
What is Unstructured Data in AI?
Unstructured data in AI refers to the information that does not have a predefined format, model, or organized structure, making it harder to store, search, and analyze using traditional databases.
— The contract that your legal team spent three weeks negotiating.
— The email thread where a client first flagged the risk that eventually cost you a renewal.
— Board meeting minutes saved as a Word document.
— Voice notes exchanged between team members.
— Live chat conversations with frustrated users.
— App store reviews explaining feature gaps.
According to IDC, global unstructured data volumes reached 180 zettabytes by 2025. For context: one zettabyte is a trillion gigabytes. And it is growing 3 times faster than structured data. Experts warn that without governance and control over unstructured information, there is no reliable AI. Poorly trained models, biases, and poor results are the consequences of ignoring this kind of data.
Why Generative AI Changed Everything — and Nothing (Yet)
How does generative AI handle unstructured data? And can generative AI read unstructured data? Large language models arrived and, in one sense, solved the reading problem. GPT-4, Claude, and Gemini can read and comprehend AI unstructured data with a fluency that earlier NLP systems could not approach.
However, connecting a powerful language model to the right enterprise data — securely, accurately, at scale — is an engineering problem that most organizations underestimated. Deploying ChatGPT on top of a SharePoint folder is not the same as building a production-ready generative AI for unstructured data over your entire document estate. The difference shows up in hallucinations, compliance failures, access control violations, and eventual executive disillusionment.
The Three Failure Modes Enterprises Keep Hitting
First, there is the hallucination trap: asking a general-purpose LLM about your specific contracts, policies, customer history, and receiving a confident but fabricated answer. In 2024, 47% of enterprise AI users reported making at least one significant business decision based on a hallucinated output. It is especially dangerous in legal, finance, or healthcare contexts.
Second, there is the security and access problem. Unstructured enterprise data is not homogeneous. A CFO's document permissions differ from a sales rep's. A patient record should not surface in response to a query from a billing department. Early enterprise AI deployments that ignored role-based access controls created exactly this kind of data exposure.
Third, there is the freshness problem. LLMs are trained on data with a cutoff date. While your internal knowledge — policies, product updates, contract amendments — changes daily. A model that was fine-tuned on last year's handbook will give your employees incorrect guidance about this year's processes.
Is your unstructured data ready for AI?
Most enterprises discover they have a data preparation gap weeks into their AI project — not weeks before. Answer 8 quick questions and find out where you stand — and what to do next.
RAG: The Architecture That Connects AI to Your Documents
Instead of asking an AI to remember everything it was ever trained on, you give it the ability to look things up — in your specific document repositories, in real time, with RAG (Retrieval-Augmented Generation) and the same access controls your existing systems enforce.
RAG gives you an AI for unstructured data that answers questions from your documents, cites the source for every claim, respects your permissions model, and updates its knowledge whenever your documents do, without requiring you to retrain a model every time a policy changes.
According to Databricks, 60% of enterprise LLM deployments currently use RAG as their primary grounding architecture. The global RAG market, valued at $1.2 billion in 2024, is projected to reach $11 billion by 2030 — a 49% compound annual growth rate.
Four Document Types Transforming Operations
The best way to understand what AI on unstructured data actually delivers is to follow the documents that flow through a typical enterprise. Let us look at four of them in detail.
1. Contracts
Contract review is one of the most expensive and slowest processes in any organization. A single commercial contract negotiation involves multiple rounds of markup, comparison against playbooks, identification of non-standard clauses, and coordination across legal, commercial, and finance. Done manually, this can take weeks and cost thousands of dollars per contract.
AI-powered contract intelligence changes the calculus entirely. A trained document AI can review a 150-page agreement in under two minutes, flagging every clause that deviates from your standard positions, identifying key obligations and expiration dates, and cross-referencing terms against prior agreements with the same counterparty.
The deeper opportunity is portfolio-level contract intelligence. Most enterprises with more than 10,000 active contracts have no reliable way to answer the question: "Which of our contracts expose us to liability if supplier X fails to deliver by December?" Before AI, answering that question required a human search party. With a properly built RAG system over your contract repository, it becomes a 30-second query.
💰 THE HIDDEN COST
but searching all day
112
full-time employees lost
to unproductive search daily
of their time = $9M/year
$9M
wasted annually
at $80K fully-loaded cost
workday — gone
1.8h
per knowledge worker
lost every single day
If you have 500 knowledge workers each wasting 1.8 hours daily searching for information, you are losing the equivalent of 112 full-time employees to unproductive search — every single day. At an average fully-loaded cost of $80,000 per employee, that is $9 million annually.
2. Emails
The average knowledge worker spends 28% of their workweek managing email, according to McKinsey, making it simultaneously the most-used and least-analyzed communication channel in most enterprises. Somewhere inside your email environment is the complete story of every customer relationship, every internal escalation, and every negotiation your company has ever conducted.
Enterprise AI applied to email does three distinct things that matter to a C-suite audience. It enables:
✅ Intelligent search: instead of keyword-matching across archives, a semantic search layer lets your teams ask "What did our largest customer say about delivery timelines in Q3?" and receive a synthesized answer with citations.
✅ Relationship intelligence: automatic detection of relationship health signals across the full scope of customer communications, not just the CRM entries that salespeople remembered to log.
✅ Compliance monitoring: automated identification of emails that contain sensitive disclosures, regulatory commitments, or contractual obligations that should have triggered formal processes but did not.
Answer three quick questions and we'll point you to the AI use case with the fastest, clearest ROI for your organisation.
Where does your team lose the most time to manual, repetitive document work?
What outcome matters most to your leadership team right now?
How would you describe your document situation today?
3. Support Tickets
Every support ticket is a structured signal from someone who cares enough about your product to document a problem with it. The aggregate of your ticket corpus is one of the richest sources of product intelligence, operational failure patterns, and churn risk signals available to any organization.
For your product and operations teams, the more transformative application is retrospective analysis. AI for unstructured data across your full ticket history — properly indexed and queryable — can tell you:
- which product areas generate the highest friction in the first 90 days of customer life;
- which failure modes correlate with eventual churn;
- which support interactions, despite being "resolved," left customers dissatisfied based on the language they used in follow-up.
With the right AI architecture, it becomes an always-on insight layer.
4. PDFs
PDFs are simultaneously ubiquitous, trusted, and completely inaccessible to machines without significant preprocessing. Reports, audits, technical manuals, regulatory filings, insurance policies, clinical studies — all of them live in PDF, and almost none of them can be searched semantically, summarized on demand, or cross-referenced with other documents without manual intervention.
Modern AI document processing changes this through a multi-stage pipeline:
OCR converts scanned or image-based PDFs into machine-readable text;
NLP models classify, chunk, and extract structured metadata;
RAG makes that extracted knowledge queryable.
Modern AI systems achieve accuracy rates of 95 to 99% on document extraction, according to a 2026 analysis of Hyperscience, Docsumo, Rossum, and comparable platforms — up from the 60 to 70% accuracy of legacy OCR-only approaches.
The business impact is most visible in industries where PDFs carry regulatory or contractual weight. Financial services firms are using AI to analyze thousands of fund prospectuses simultaneously. Healthcare organizations are extracting structured clinical insights from unstructured patient records. Insurance carriers are automating claims processing from documents that previously required hours of human review per case.
According to IDP vendor research,
most organizations see measurable ROI within 6 to 12 months of deployment in high-volume document processes — not 18 to 24 months as with traditional enterprise software. Contact us to explore where AI can deliver the fastest wins in processing and extracting value from your unstructured data.
Beyond RAG: What Agentic AI Adds to the Picture
Retrieval-Augmented Generation (RAG) marked an important step forward — enabling AI systems to ground their responses in enterprise-specific knowledge rather than relying solely on pre-trained information. However, RAG remains reactive: it answers questions when asked. The next wave — agentic AI — is beginning to reshape what is possible. What is the AI solution for unstructured data?
Agentic systems monitor document inflows, identify patterns across content streams, trigger workflows based on what they find, and take actions — routing a contract for review, escalating a support case, flagging a regulatory anomaly — without requiring a human first to ask the right question.
In legal operations, an agentic system might continuously monitor incoming vendor agreements, detect non-standard indemnification clauses, and automatically route flagged documents to the appropriate counsel — before any paralegal opens their inbox.
In financial services, agents can watch transaction streams for compliance anomalies, cross-reference them against evolving regulatory guidance, and escalate potential violations in near-real time. In enterprise support, they can detect when a ticket cluster signals an emerging infrastructure issue, correlate it with recent change logs, and page the relevant engineering team.
The practical implication for enterprise leaders is to start with tightly scoped agents in low-risk contexts, build institutional trust through demonstrated accuracy, and expand the autonomy envelope gradually as the evidence base grows. This extends beyond internal operations. As AI-powered experiences such as Google AI Mode increasingly rely on structured information to generate relevant responses, the same principles of data quality and organization remain essential for maximizing enterprise value.
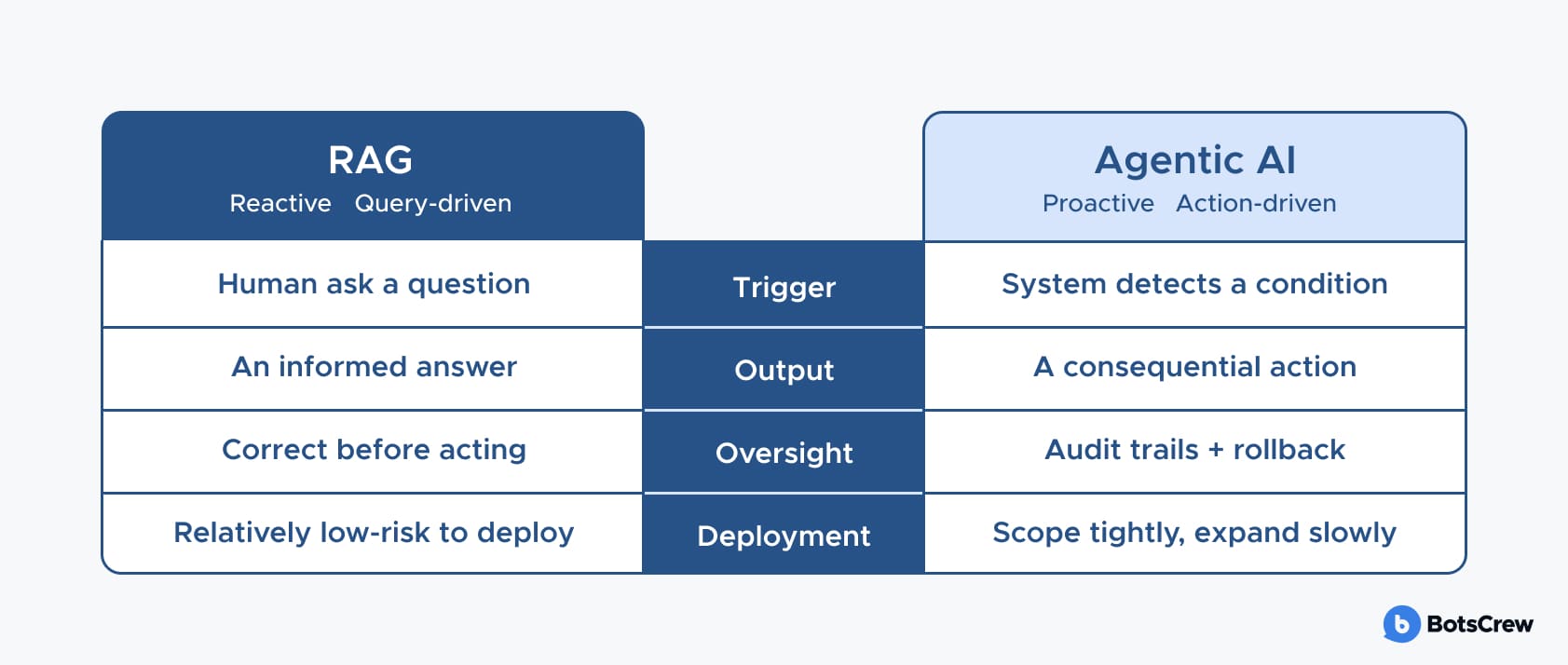
The diagram above captures the core contrast. The most mature enterprise deployments will likely combine both layers — RAG for knowledge grounding, AI agents for workflow execution.
A Practical Roadmap: How to Manage Unstructured Data for AI
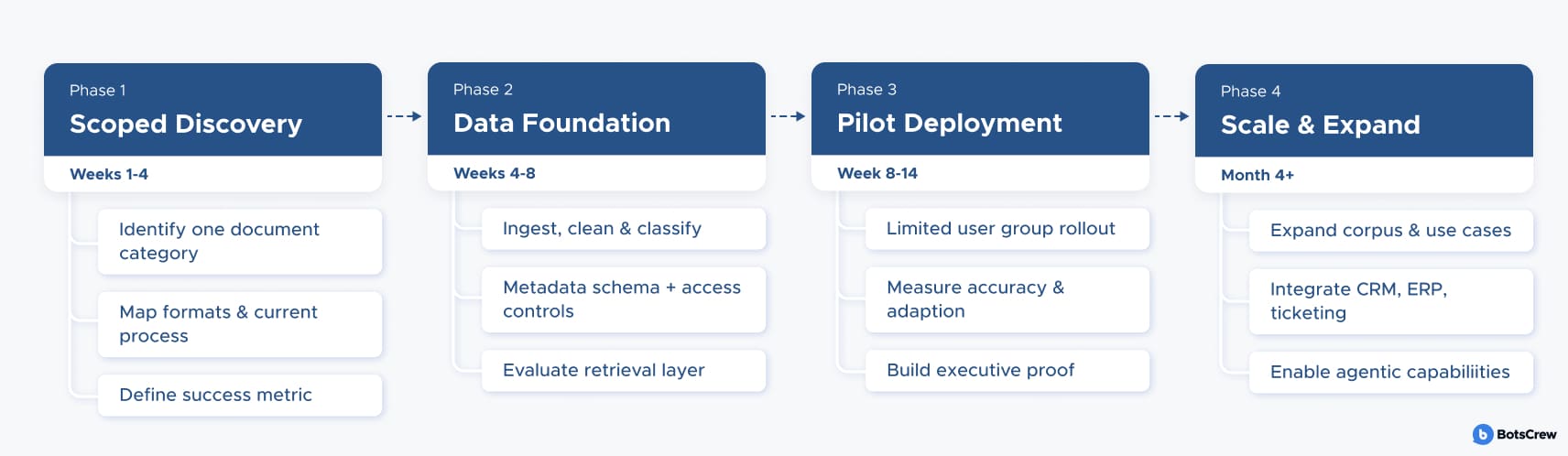
Phase 1: Scoped Discovery (Weeks 1–4)
Identify one high-value, high-volume document category. Map where it lives, what formats it comes in, what the current human process for working with it looks like, and what the measurable outcome improvement would look like. The goal is a crisp problem statement with a quantifiable success metric.
Example: a professional services firm identifies vendor contracts as the target: 4,000 agreements across SharePoint and personal drives, reviewed manually by a paralegal before each renewal. The current process takes 25 minutes per contract. Success metric: under 3 minutes.
Phase 2: Data Foundation (Weeks 4–8)
Ingest, clean, classify, and chunk the target document set. Establish your metadata schema. Integrate with your identity provider for access controls. Build the retrieval layer and evaluate it against a test set of real queries before any UI is built.
Example: all 4,000 contracts are ingested, chunked by clause type, and tagged with metadata — counterparty, contract type, jurisdiction, owner. Role-based access limits sensitive clause retrieval to the legal team. Retrieval is validated against 80 real queries before any interface is built.
Phase 3: Pilot Deployment (Weeks 8–14)
Deploy to a limited user group with structured feedback collection. Measure retrieval accuracy, answer faithfulness, user adoption, and business outcome metrics simultaneously. This phase generates the organizational proof that unlocks executive commitment to scale.
Example: eight legal ops team members run the system alongside their existing workflow. By week four, adoption is at 75% and average clause-lookup time is 2.5 minutes. Three edge cases surface around multi-jurisdiction contracts and are fed back into the chunking pipeline before broader rollout.
Phase 4: Scale and Expand (Month 4 onward)
Expand the document corpus, extend to adjacent use cases, integrate with downstream systems (CRM, ERP, ticketing), and begin the governance work needed to support agentic capabilities. The cost of scaling a well-designed RAG system is primarily data and compute — not a rebuild of the architecture.
Example: HR policy documents and procurement SOPs are added in under 2 weeks each, reusing the existing pipeline. The system connects to the firm's matter management platform. Audit logs and human review checkpoints are put in place ahead of an agentic layer that will auto-flag renewal anomalies without waiting for a paralegal to run the search.
You don't need a bigger data team. You need the right AI partner.
We've built production AI systems for enterprises navigating exactly this — fragmented documents, legacy infrastructure, and pressure to show results fast. We know where implementations stall, what governance requires, and how to make the investment pay back in quarters, not years.
Schedule a Discovery CallAI Unstructured Data: Core Concepts and Definitions
Below, we've highlighted the top AI solutions for managing unstructured data, with the simple explanation for non-techies:
RAG — Retrieval-Augmented Generation. A technique that gives an AI model the ability to look up information from your specific documents before answering, rather than relying only on what it was trained on.
LLM — Large Language Model. The type of AI model behind tools like ChatGPT, Claude, and Gemini. Trained on vast amounts of text, it can read, summarise, write, and reason — but it only knows what it was trained on, which is why RAG matters.
NLP — Natural Language Processing. The branch of AI that enables computers to understand, interpret, and generate human language. Every time an AI reads a contract clause or classifies a support ticket, it is using NLP.
OCR — Optical Character Recognition. Software that converts images of text — scanned PDFs, photos of documents, faxes — into machine-readable characters that can be searched, edited, and processed by AI. The essential first step for any scanned document pipeline.
ERP — Enterprise Resource Planning. A category of business software (SAP, Oracle, NetSuite) that manages core operations: finance, HR, supply chain, inventory. ERPs are built around structured data — which is why unstructured documents are largely invisible to them.
GenAI — Generative AI. AI systems that create new content — text, images, code, audio — rather than just classifying or predicting. GPT-4, Claude, and Gemini are all generative AI models.
Agentic AI. An AI system that doesn't just answer questions — it takes actions autonomously. An agent can monitor incoming documents, detect patterns, trigger workflows, and route tasks without a human prompting it at each step of the way.