




AI Security Concerns & 5 Ways to Protect Data in AI Development
As AI TRiSM (AI Trust, Risk, and Security Management) becomes a boardroom priority, AI security concerns are increasingly driving executive decisions. Organizations are pushing to adopt resilient, privacy-centric systems to safeguard against legal exposure and reputational harm. Here is how businesses can drive this transformation.


More than half of global businesses lack effective defense strategies against AI security concerns, even though they are increasingly concerned about the growing AI security risks. However, most are taking steps to address the issue.
Strengthening AI risk management has emerged as one of the leading AI security trends for 2025. We’ve outlined the leading approaches business leaders are adopting to develop AI systems that are secure, fair, and trustworthy — while minimizing privacy risks.

Privacy Risks in the Age of Generative AI
As generative AI tools like ChatGPT, DALL·E, and others become integral to enterprise operations, the urgency to manage associated security risks of generative AI has intensified. These models process vast amounts of data to generate human-like responses, images, or code — but this sophistication comes with substantial exposure to AI privacy and security vulnerabilities.
Let's break down the most pressing generative AI security risks and explore why robust safeguards — including using secure networks, VPNs, and encryption — are no longer optional, but essential.
#1. Data Exposure and Sensitive Information Leaks. Generative AI rapidly enhances cybercriminals' capabilities, driving a surge in sophisticated social engineering and phishing attacks.
In 2024, 42% of organizations reported experiencing cyberattacks. Furthermore, 72% of business leaders now report a rise in overall cyber risk, with ransomware continuing to top the list of concerns. More notably, 47% cite adversarial use of generative AI as a primary risk factor — pointing to AI's growing role in enabling highly targeted, scalable, and convincing attack vectors. Data breaches often stem from improperly secured training data, weak access controls, or misconfigured APIs.
👀 For instance, in early 2023, Samsung banned the internal use of ChatGPT after an employee inadvertently entered sensitive source code into the platform. This highlighted how easily proprietary data can escape a company's control when using public AI systems, underscoring the critical need for AI security framework and prompt injection mitigation measures.
Without strict data governance, even anonymized datasets can leak insights that can be traced back to individuals or expose competitive information. With cybersecurity becoming central to responsible AI innovation, those holding an online cyber security masters bring crucial expertise in encryption protocols, access control, and data integrity — all essential for protecting sensitive information throughout the AI lifecycle.
#2. Unintended Data Sharing (Proprietary or Personal Information). Many generative AI tools interface with external APIs or cloud services, raising the risk of unintended data sharing. Even if users don't explicitly consent, their data can be retained, reused, or shared across model updates.
This creates a potential legal minefield under regulations like the GDPR, CCPA, or China's PIPL, highlighting the importance of AI vulnerability management and enterprise AI security controls.
#3. Training on Unsecured or Sensitive Datasets. When generative models are trained on unvetted datasets, including emails, health records, or internal documentation, they can inadvertently memorize and regurgitate sensitive snippets during everyday use. This issue becomes critical when the model is deployed publicly or integrated into customer-facing applications.
😱 A study by UIUC and Stanford University researchers found that large language models could reproduce specific social security numbers, names, and emails that were included in their training data — even if that data was supposedly anonymized.
Companies must ensure that all training data is thoroughly scrubbed, encrypted, and vetted for regulatory compliance to mitigate gen AI data security risks.
#4. Adversarial Threats: Data Extraction and Reconstruction. Generative models are increasingly vulnerable to adversarial attacks — techniques where attackers deliberately probe AI systems to extract or reconstruct sensitive data. These attacks exploit model behaviors to reveal confidential training inputs, sometimes with shocking precision.
😶🌫️ In a 2022 academic experiment, researchers successfully extracted sensitive medical details from a fine-tuned GPT model used by a healthcare company simply by crafting targeted prompts.
These attacks can compromise intellectual property, expose personal information, or even reveal strategic business operations. As AI capabilities grow, so does the sophistication of potential threats, making AI risk management and AI security assessment indispensable.

5 Techniques for Ensuring Data Privacy in AI Development
In this section, we explore the most effective techniques for protecting user data and minimizing exposure risks, including anonymization, encryption, differential privacy, and more.
Data Anonymization and Pseudonymization
AI systems increasingly rely on large volumes of personal and sensitive data and data security in AI through data anonymization and pseudonymization have become vital techniques for safeguarding privacy and ensuring compliance with regulations like GDPR, HIPAA, and CCPA.
Although both anonymization and pseudonymization protect personally identifiable information (PII), they function differently — and are suitable for different use cases.
|
Tech- nique |
Description |
Re-identification Risk |
Example |
|
Anony- mization |
Permanently removes personal identifiers to prevent re-identification. |
Very low |
Replacing names with random IDs, generalizing age |
|
Pseudo- Nymi- zation |
Replaces identifiers with codes, keeping a key for possible re-identification. |
Moderate |
Replaces customer names with IDs linked via a separate mapping table. |
🕵🏻♂️ Anonymization is used when the goal is to eliminate any link to an individual. This is critical for datasets shared publicly or used for model training where no follow-up with the data subjects is needed.
🕵🏻 Pseudonymization, on the other hand, allows organizations to secure individual-level tracking. It is commonly used in healthcare, finance, or support operations where data may need to be re-linked under controlled conditions.
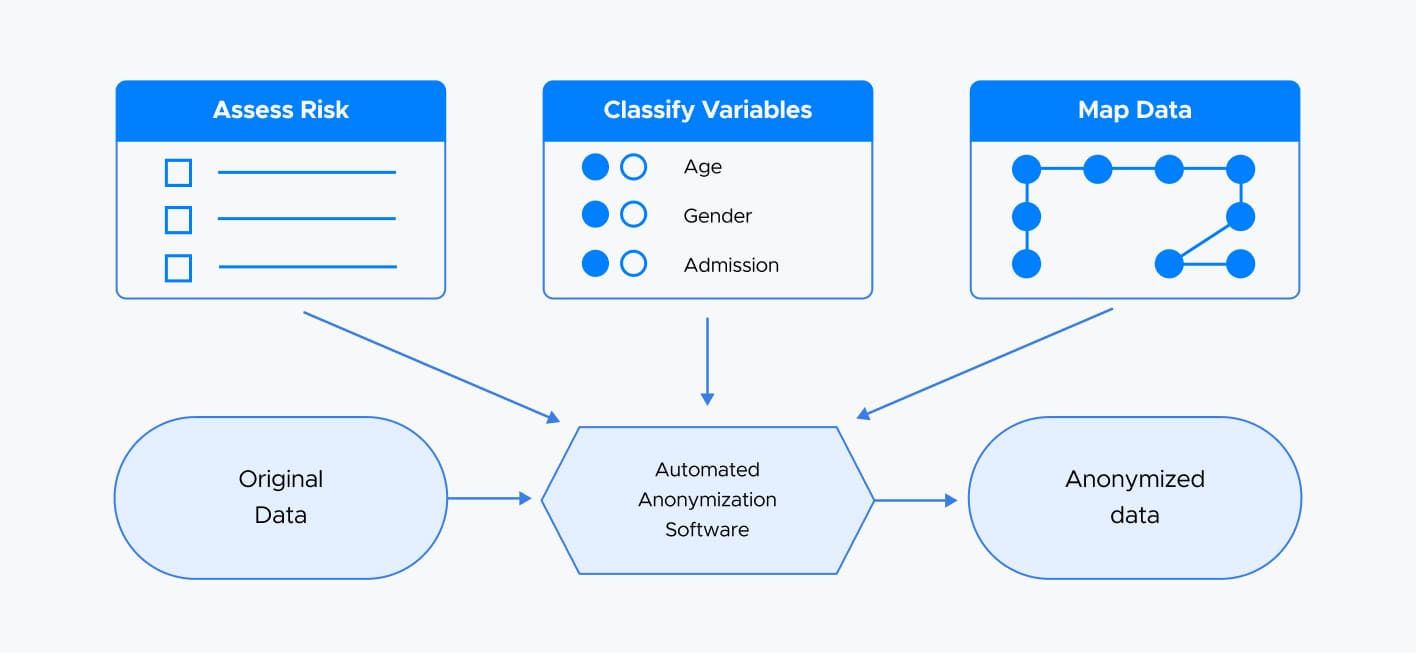
Virtually any organization using AI that touches personal or sensitive data will benefit. Key stakeholders include:
- Healthcare Providers: Comply with HIPAA/GDPR while enabling AI-powered diagnostics or treatment suggestions.
- Financial Institutions: Detect fraud or personalize services without exposing raw customer data.
- Public Sector and Research Institutions: Share open data for the public good without compromising citizen privacy.
- Compliance Officers and CISOs: Strengthen risk posture and reduce breach liability.
Best practices for implementation: to ensure effective and compliant use of anonymization and pseudonymization, organizations should
✅ Adopt a layered approach. Combine these techniques with encryption, strict access controls, and audit logging to build defense-in-depth.
✅ Secure the re-identification key (for pseudonymization). Store the mapping key in a separate, highly secured system, with access limited to authorized personnel only.
✅ Continuously test for re-identification risks. Run regular assessments to ensure anonymized data can't be de-anonymized with external datasets.
✅ Document and validate methods. Regulators and auditors may require evidence of your de-identification processes and their effectiveness.
Secure Multi-Party Computation
While anonymization and pseudonymization remove or obscure identifiers within a single dataset, Secure Multi-Party Computation (SMPC) addresses a different challenge: how multiple parties can jointly compute insights over their combined data — without ever revealing their raw inputs. This makes SMPC an indispensable technique when collaboration and confidentiality must coexist.
How SMPC Works:
Secret Sharing of Inputs. Each participant splits their private data into cryptographic shares. Alone, a share reveals nothing about the original value; only by recombining a threshold number of shares can the accurate input be reconstructed.
Encrypted Computation. All computations (additions, multiplications) are performed on the shares themselves. At no point does any party see another's raw data, yet the group collectively executes the same function as if they had pooled their cleartext inputs.
Result Reconstruction. Once the calculations finish, each party holds a share of the result. By bringing together those result-shares, they recover the final output — again, without ever exposing individual inputs.
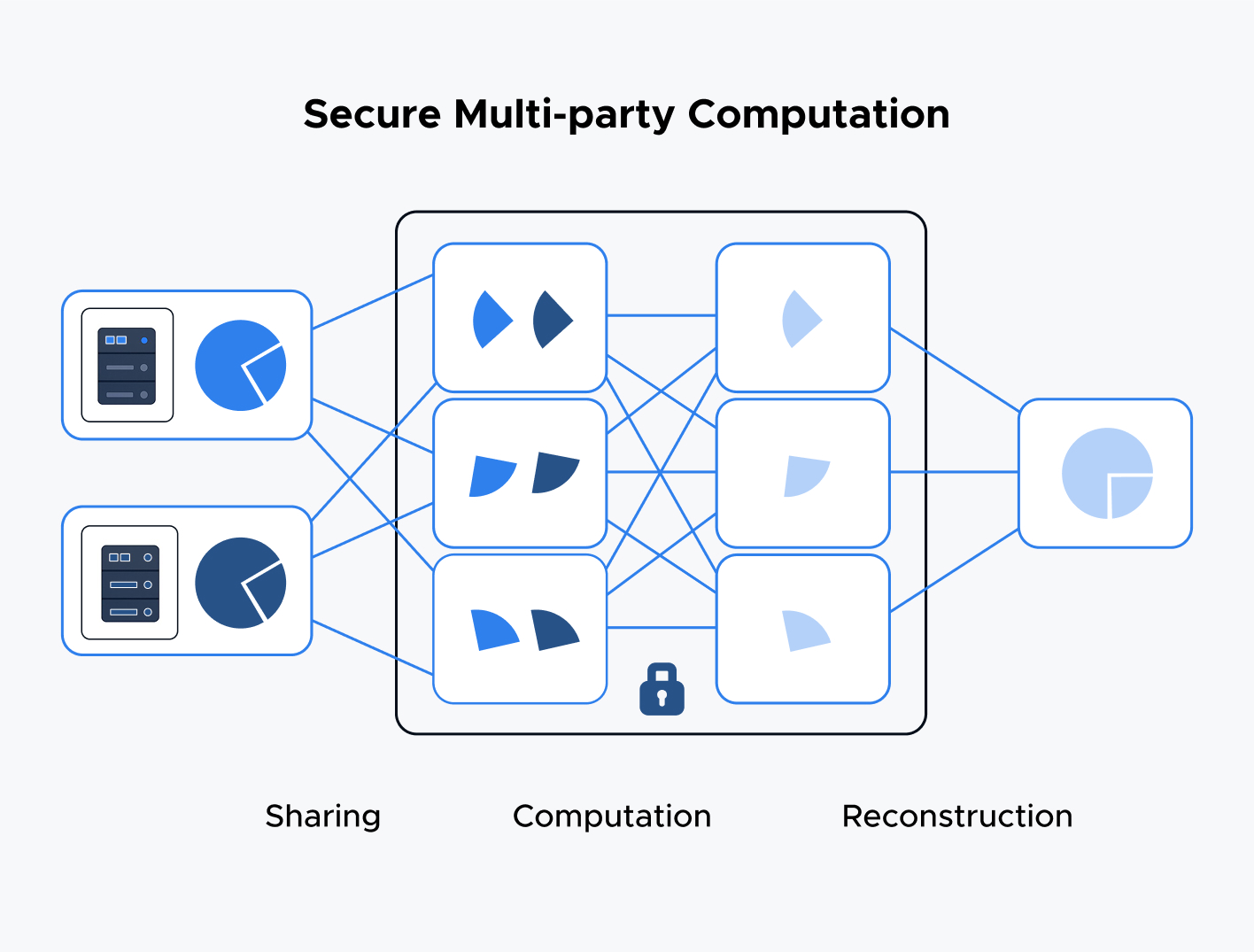
SMPC vs. Anonymization & Pseudonymization
|
Aspect |
Anonymization/Pseudonymization |
SMPC |
|
Purpose |
De-identify single datasets |
Jointly compute on multiple private datasets |
|
Data Visibility |
Raw data is transformed or hidden |
Raw data never leaves the owner's control |
|
Re-identification Risk |
Anonymization: minimal Pseudonymization: moderate (with key) |
Zero — other parties see only encrypted shares |
|
Use Cases |
Public data release, model training |
Cross-organization analytics, secure auctions |
Who Benefits Most from SMPC:
- Healthcare Consortia: Multiple hospitals or research centers can collaboratively analyze patient outcomes — e.g., for rare diseases — without exposing individual medical records.
- Financial Institutions: Banks can jointly detect fraud patterns or calculate shared risk metrics without sharing proprietary customer data.
- Government Agencies: Different departments (tax, social services, law enforcement) can correlate insights on public programs without sharing sensitive citizen records.
- Scientific Collaborations: Research teams across universities can pool genomic or survey data for large-scale studies while adhering to strict privacy regulations.
Best practices for implementation:
✅ Threat Model & Collusion Resistance. Define the maximum number of parties that could collude. Ensure your SMPC setup enforces security even if a subset of participants attempts to cheat — a critical aspect of AI model security.
✅ Integration with Other Controls. Combine SMPC with encryption-at-rest, strict access controls, and audit logging to build a defense-in-depth strategy.
✅ Regulatory Alignment. While SMPC doesn’t generate personal data leaks, document your protocol choices and risk assessments to satisfy auditors and regulators.
Differential Privacy
Differential Privacy is an innovative method for helping organizations share valuable insights about groups of people — without revealing anything about any one individual.
Think of differential privacy, like adding a bit of noise or fuzziness to the data. This noise makes it very hard for anyone to figure out if a specific person's data is included in the results. You get useful overall trends and patterns without risking anyone's private details.
How does it work:
- When a question is asked about the data (How many people used our app last month?), the system adds some randomness to the answer to protect individuals.
- There is a balance to strike: more noise means better privacy but less precise answers; less noise means more accurate answers but slightly less privacy.
- This process makes it nearly impossible to identify anyone based on the shared information.
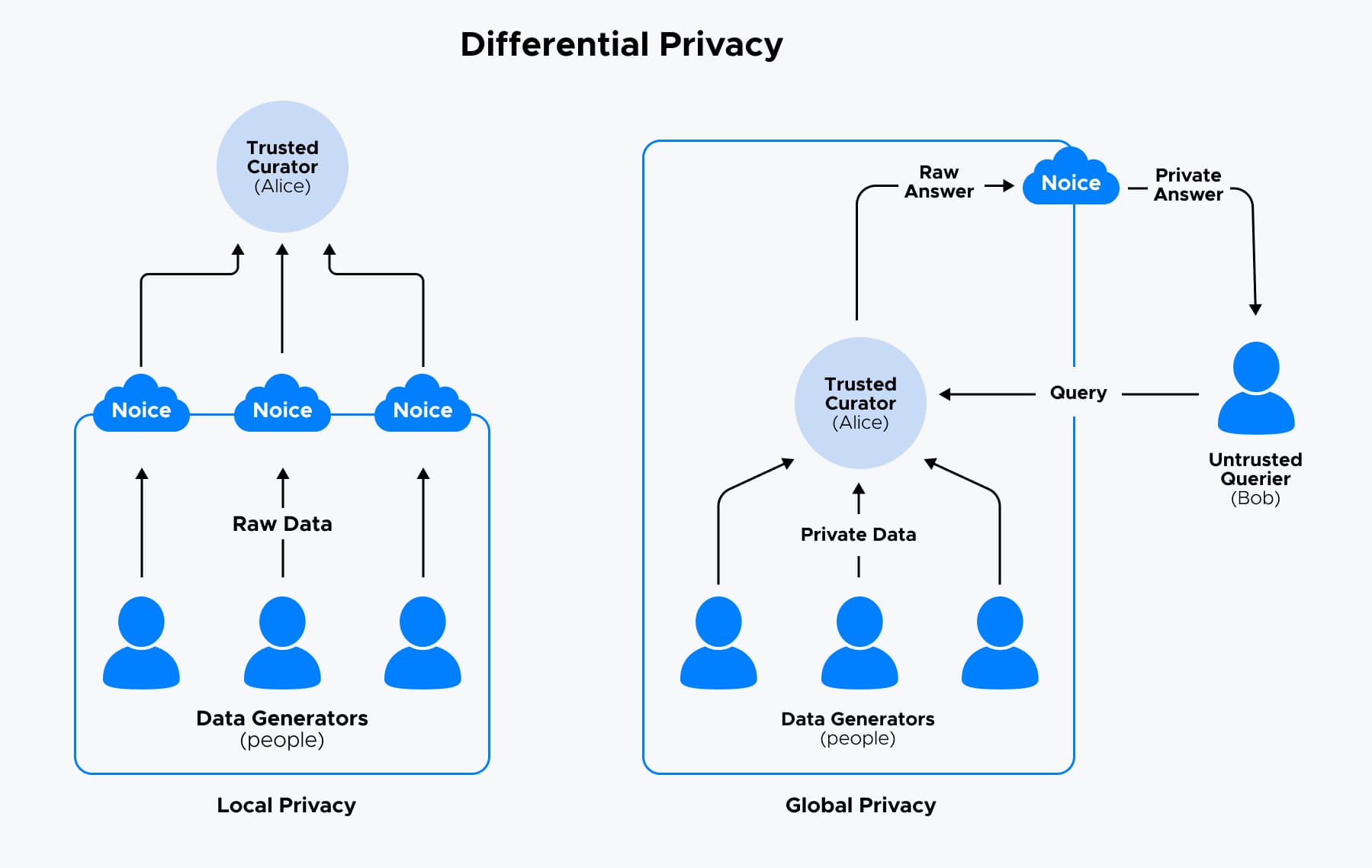
How Is Differential Privacy Different from Other Privacy Methods:
|
Privacy Method |
What It Does |
When It’s Used |
|
Data Anonymization |
Removes or hides names and IDs from data |
When sharing datasets or reports |
|
Secure Multi-Party Computation |
Enables joint data analysis without sharing raw data. |
When collaborating on sensitive data without exposing it. |
|
Differential Privacy |
Adds noise to data results to protect individuals |
When sharing trends without exposing private data. |
Who Benefits from Differential Privacy:
- Tech companies like Apple and Google which collect user data to improve services while respecting privacy.
- Government agencies that publish census or health statistics safely.
- Businesses and researchers wanting to share insights or build AI models without exposing individual customer data.
The amount of noise added needs to be carefully managed to keep insights functional. It's also crucial to keep in mind that differential privacy is just one part of a bigger privacy strategy — often combined with other tools.
Don't leave data privacy to chance. Schedule a free call with our AI development team to explore how we can help you build trustworthy, secure AI systems that meet today's regulatory standards and your unique business goals.
Data Masking
Data masking is a powerful security technique that replaces real sensitive information with scrambled or fake data that looks structurally similar to the original. This approach enables AI systems and analytics tools to work with realistic datasets without exposing confidential details, ensuring privacy while maintaining data usability.
How does it work:
— First, the system locates which data needs masking — names, social security numbers, credit card details, or email addresses.
— Depending on the data type, specific masking techniques are applied. For example:
Substitution: Replacing real data with fake but plausible alternatives (e.g., swapping real names for random names).
Shuffling: Randomly rearranging existing data within the dataset to break the link to the original.
Masking Out: Replacing parts of the data with symbols (e.g., showing only the last four digits of a credit card as **** **** **** 1234).
Encryption: In some cases, sensitive data is encrypted strings that only authorized systems can reverse.
— The masked data looks and behaves like the original data, so it can be used for testing, training AI models, or analysis without errors when processed through a training agent.
— The system then uses this masked data in development, analytics, or sharing — ensuring the real sensitive data is never exposed during these processes.
How Data Masking Differs from Other Privacy Techniques:
|
Privacy Technique |
What It Does |
Key Use Cases |
|
Data Anonymization & Pseudonymization |
Removes or replaces identifiers to prevent tracing data back to individuals |
Sharing or publishing data without revealing identities |
|
Secure Multi-Party Computation (SMPC) |
Allows multiple parties to jointly analyze data without revealing their own inputs |
Collaborative computations between organizations with sensitive data |
|
Differential Privacy |
Adds calculated “noise” to query results to protect individual privacy in published statistics |
Sharing aggregate data or insights publicly while preserving privacy |
|
Data Masking |
Substitutes sensitive data with realistic but fake values to protect privacy while retaining data format and patterns |
Secure testing, development, AI training, and safe data sharing |
For instance, a social security number 123-45-6789 might be masked as XXX-XX-6789 or replaced with a fake but plausible number that keeps the format intact. This way, systems can analyze data patterns or validate processes without seeing the real identifier.
Who Should Use Data Masking:
- Financial institutions handling credit card numbers, social security numbers, or other highly sensitive customer data.
- Healthcare providers processing patient records, where confidentiality is critical.
- Enterprises running AI or software development projects that require realistic data for training or testing without exposing real personal information.
- Any organization sharing data across departments or external partners that needs to balance accessibility with strict privacy controls.
Homomorphic Encryption
Encryption, including homomorphic encryption, is a fundamental requirement for protecting sensitive information, especially under regulations like PCI DSS (Payment Card Industry Data Security Standard) and HIPAA (Health Insurance Portability and Accountability Act).
It is a cutting-edge cryptographic method that allows computations to be performed directly on encrypted data without ever needing to decrypt it first. When decrypted, the result exactly matches the result as if the operations were done on the original raw data. This means sensitive information can stay encrypted and protected even while being processed, drastically reducing the risk of exposure during data analysis or machine learning.
How does it work:
- Encryption: Data is encrypted by the owner using a special key. The encrypted data (ciphertext) is meaningless and secure for storage or transmission, even over untrusted environments like public clouds.
- Computation: A computation algorithm (potentially run by a third party such as a cloud provider) performs calculations directly on the ciphertext. Thanks to the homomorphic property, these operations mirror what would happen on the original data, without revealing any sensitive content.
- Decryption: The encrypted result of the computation is sent back to the data owner, who uses a private key to decrypt it. The decrypted output matches exactly what you’d get if you had processed the original, unencrypted data.
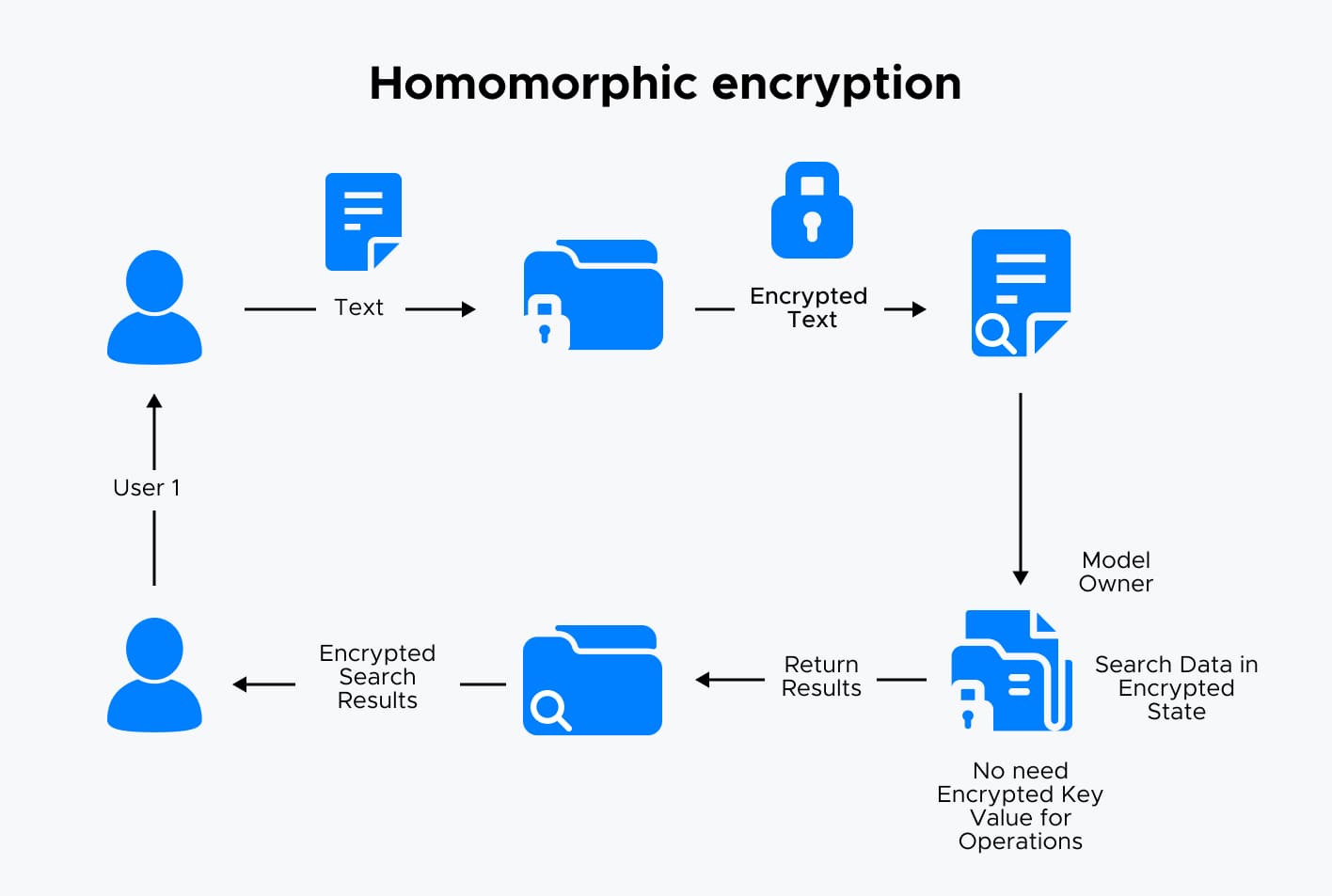
|
Privacy Technique |
How It Works |
When Data Is Processed |
Key Benefit |
|
Homomorphic Encryption |
Performs computations directly on encrypted data without decrypting it first |
Data remains encrypted during processing |
Protects raw data throughout processing |
|
Anonymization & Pseudonymization |
Removes or replaces identifying details, but data is usually decrypted for processing |
Data is typically decrypted for processing |
Reduces risk of re-identification |
|
Secure Multi-party Computation (SMPC) |
Data split into secret shares and computations are done jointly without revealing inputs |
Data split among multiple parties; processed collaboratively |
Enables privacy-preserving joint computation |
|
Differential Privacy |
Adds controlled noise to results to protect individual data privacy while allowing aggregate insights |
Data is processed and noisy results are shared |
Balances privacy and data utility |
|
Data Masking |
Replaces sensitive data with fake but realistic data for safe use in development/testing environments |
Data is modified before use |
Safely tests or shares data without exposing real info |
This advanced technique is especially valuable for organizations that must process highly sensitive data while preserving strict privacy and security, such as:
- Healthcare providers running AI diagnostics on encrypted patient records without exposing raw data.
- Financial institutions performing risk analysis or fraud detection on encrypted transaction data.
- Businesses using cloud computing for sensitive operations that need to ensure data confidentiality from cloud providers.
- Government agencies conducting secure data analytics while complying with privacy regulations.
While homomorphic encryption requires significant computing power, ongoing research improves its efficiency. As these advancements continue, homomorphic encryption promises to become a cornerstone of privacy-first AI and data processing strategies in regulated and high-risk environments.
Other Best Practices to Mitigate AI Privacy Risks
Beyond fundamental principles like data minimization and access control, there are several additional best practices that organizations must adopt to manage and mitigate privacy risks associated with AI systems effectively:
Leverage Data Minimization
By limiting data collection to what is strictly needed, organizations can significantly reduce the risks associated with data breaches, unauthorized access, and misuse of sensitive information.
Clearly define the purpose for which data is collected before acquisition. Collect data only if it directly supports that purpose, avoiding gathering information “just in case” it might be helpful later. Limit the types and categories of data collected to those relevant to the task. For example, if an AI agent only needs anonymized demographic data for analysis, avoid collecting detailed personal identifiers like full names or contact information.
Establish clear retention policies that define how long data is stored and when it must be securely deleted. Retain data only as long as necessary to fulfill the intended purpose or comply with legal requirements, then securely delete or anonymize it.
Periodically review the data collected to identify and remove any unnecessary or redundant information. This practice ensures ongoing adherence to minimization principles as business needs evolve.
Conduct Regular Security Audits and Penetration Testing
Regular audits and penetration tests are essential to uphold data privacy and security in AI development.
✅ Vulnerability Scanning: Routinely check AI systems for known security weaknesses in code and infrastructure as part of AI vulnerability management.
✅ Penetration Testing:Simulate cyberattacks to uncover and address system vulnerabilities, including those in AI algorithms, data storage (including on prem object storage where applicable), and communication channels before malicious actors exploit them.
Educate Teams and Users
Data privacy and security require collective responsibility across the organization. Foster a culture of security awareness among AI developers, business leaders, and end-users.
✅ Training: Provide regular AI security training for all team members involved in AI development.
✅ User Awareness: Inform end-users how their data is used and how to protect their privacy, including adjusting settings or opting out of data collection when possible.
Partnering with a trusted and experienced software development company specializing in AI ensures that data privacy is prioritized and effectively managed throughout the AI lifecycle.
Ready to transform your business with secure AI? Book a free expert consultation and take the first step toward building trustworthy AI solutions that safeguard your data and accelerate your success.


