




What Is AI-Ready Data & How to Get Yours There
As organizations lean further into AI, one challenge keeps showing up for business leaders: AI-ready data. AI is only as good as the data behind it — and if that data isn't clean, connected, and context-rich, even the smartest models will struggle. In this article, we break down the key principles to make sure your data for AI is ready.


AI is reshaping industries at breakneck speed, and companies are racing to invest. But there is one critical misstep that keeps derailing progress: overlooking the need for properly prepared, AI-ready data.
According to Harvard Business Review, 80% of AI projects fail — primarily because of poor data quality, misaligned data inputs, or a lack of clarity around the data infrastructure AI systems truly require to succeed. Even among the most advanced enterprises, the struggle is real. Accenture reports that 61% of high-maturity organizations admit their data for AI isn't quite ready.
Many businesses get stuck in the experimentation phase, unable to scale or unlock the full value of their AI investments. In this article, we explore what it really means to have AI-ready data — and break down the practical steps fast-growing companies and enterprises can take to build a strong, scalable foundation for all types of AI.

What Is AI-Ready Data?
AI-ready data is structured, validated, and governed information that meets the specific quality, consistency, and accessibility standards required for effective AI and machine learning implementation. It is clean, structured, enriched with context, and managed in a way that enables reliable, scalable, and trustworthy AI outcomes.
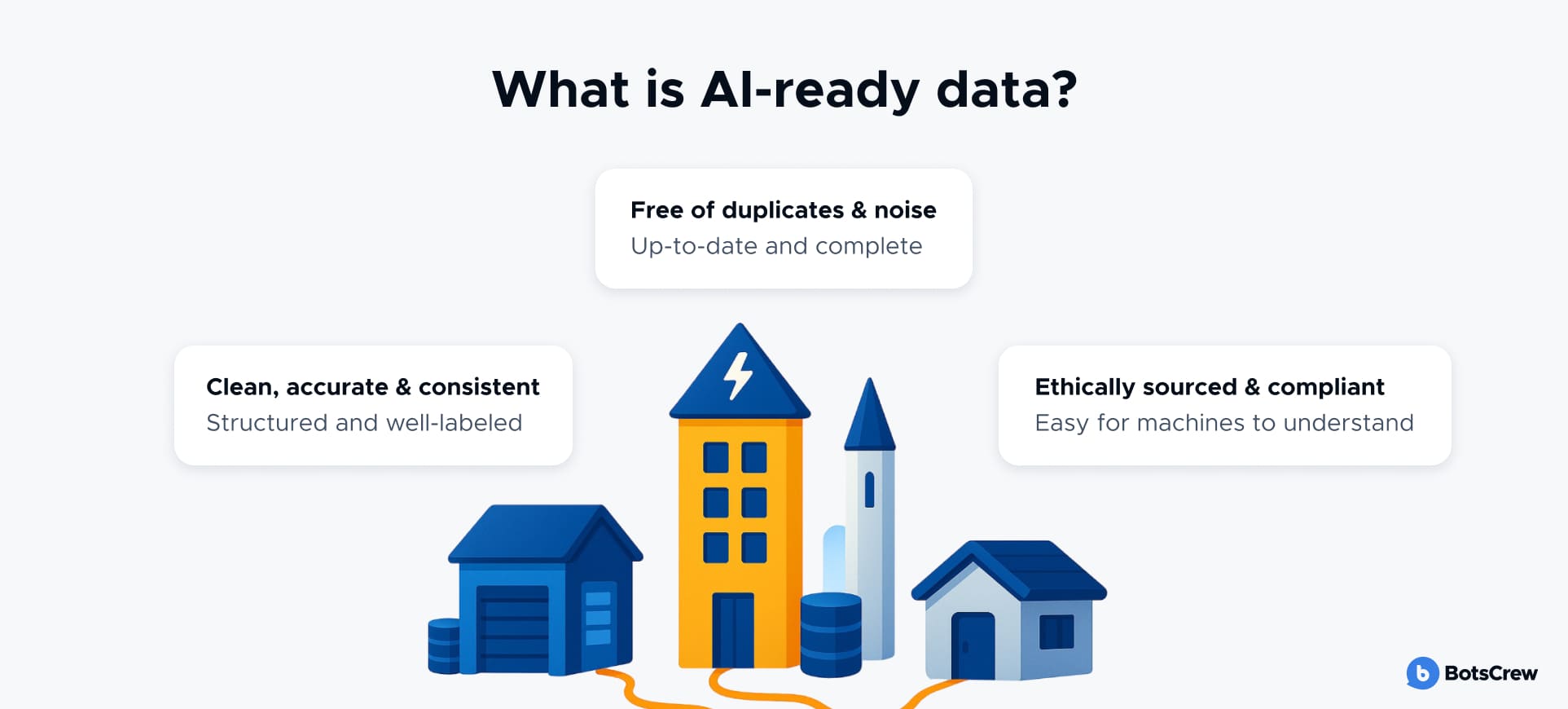
Here are a few examples of AI-ready data in different industries:
— Fraud Detection (Financial Services). Transaction data — including time, location, and amount — must be cleaned, normalized, and validated before being used. Proper preparation ensures the AI can spot subtle patterns and accurately flag suspicious activity.
— Demand Forecasting (Retail). Historical sales figures, paired with promotional calendars and product metadata, must be harmonized and structured before training forecasting models. This allows the AI to generate precise demand predictions across regions and product categories.
— Predictive Maintenance (Manufacturing). Sensor data from machinery — both historical and real-time — must be continuously collected, labeled by dedicated data labeling teams, and preprocessed. This enables AI systems to detect anomalies and predict potential failures before they occur, minimizing costly downtime.
Why Data Readiness Matters
If that data is riddled with inaccuracies, inconsistencies, or gaps, it can derail even the most sophisticated AI initiatives — producing unreliable insights, biased outputs, and ultimately, poor business decisions.
Gable CEO Chad Sanderson compares data to diet: if garbage goes in, then garbage comes out. It means that if a system is fed bad, inaccurate, incomplete, or irrelevant data, then the output — insights, predictions, or decisions — will also be flawed or misleading.
Let's explore a few real-world examples where poor data readiness can seriously undermine AI performance:
#1. Inaccurate data: the risk of misguided decisions in finance. In the financial sector, AI is revolutionizing client experiences through tools like robo-advisors, which analyze vast datasets — ranging from financial statements to real-time market feeds and news articles — to inform investment decisions.
When this data is outdated, misreported, or simply inaccurate, AI models may misinterpret a company's financial health, leading to diminished client trust.
#2. Missing or incomplete data: a hidden threat in healthcare. Predictive models in healthcare depend on comprehensive patient data, including diagnostic results, medical history, and prescribed treatments.
However, if crucial data fields are missing, the reliability of these models collapses. The result is potential misdiagnoses, overlooked health risks, or ineffective treatment plans that could put patients at risk and erode confidence in AI-powered care.
👀 According to IDC's report Activating Enterprise Data with AI and Analytics, 75% of data loses value within days, making timely preparation critical for AI accuracy. Despite this, 33% of organizations often don't use the data they collect, and 70% admit it is underutilized — highlighting a major gap in unlocking AI's full potential through better data management.

Advantages of Data Readiness
Preparing your data for AI isn't just about checking a technical box — here is what AI-ready data enables:
Better, Faster Decision-Making
When datasets are consistent, well-governed, and context-rich, AI-generated insights can be trusted to inform high-stakes moves. Take the healthcare industry. Mount Sinai Health System in New York leveraged well-curated patient data to train AI models that could predict critical illness up to 24 hours before doctors recognized it.
Reduced Time and Cost to Deploy
AI-ready data minimizes the need for manual data cleaning and reduces the complexity of model training. According to surveys, around 60% of data scientists' time is spent on data preparation, not model development.
This inefficiency delays deployments and inflates project budgets. By investing in structured, high-quality data pipelines, companies accelerate time-to-value and minimize operational drag.
Stronger Governance and Compliance
Regulatory bodies are pushing for explainability, fairness, and accountability — and none of that is possible without robust data foundations. AI-ready data provides the audit trails, transparency, and traceability needed to meet global regulations like the EU AI Act or the proposed U.S. Algorithmic Accountability Act.
Long-Term Cost Savings and Risk Reduction
Manual data cleaning, re-training, rework, and infrastructure inefficiencies drive up costs. IBM estimates that poor data quality costs U.S. businesses over $3.1 trillion annually.
Forrester also found that less than 0.5% of all available data is ever analyzed and put to use. Their research suggests that if a typical Fortune 1000 company could boost data accessibility by just 10%, it could unlock over $65 million in additional net income. These figures underscore why upfront investment in clean data pays off.
Want to unlock your company's full AI potential? 👉 Schedule your free demo and see how unified data can supercharge your AI.
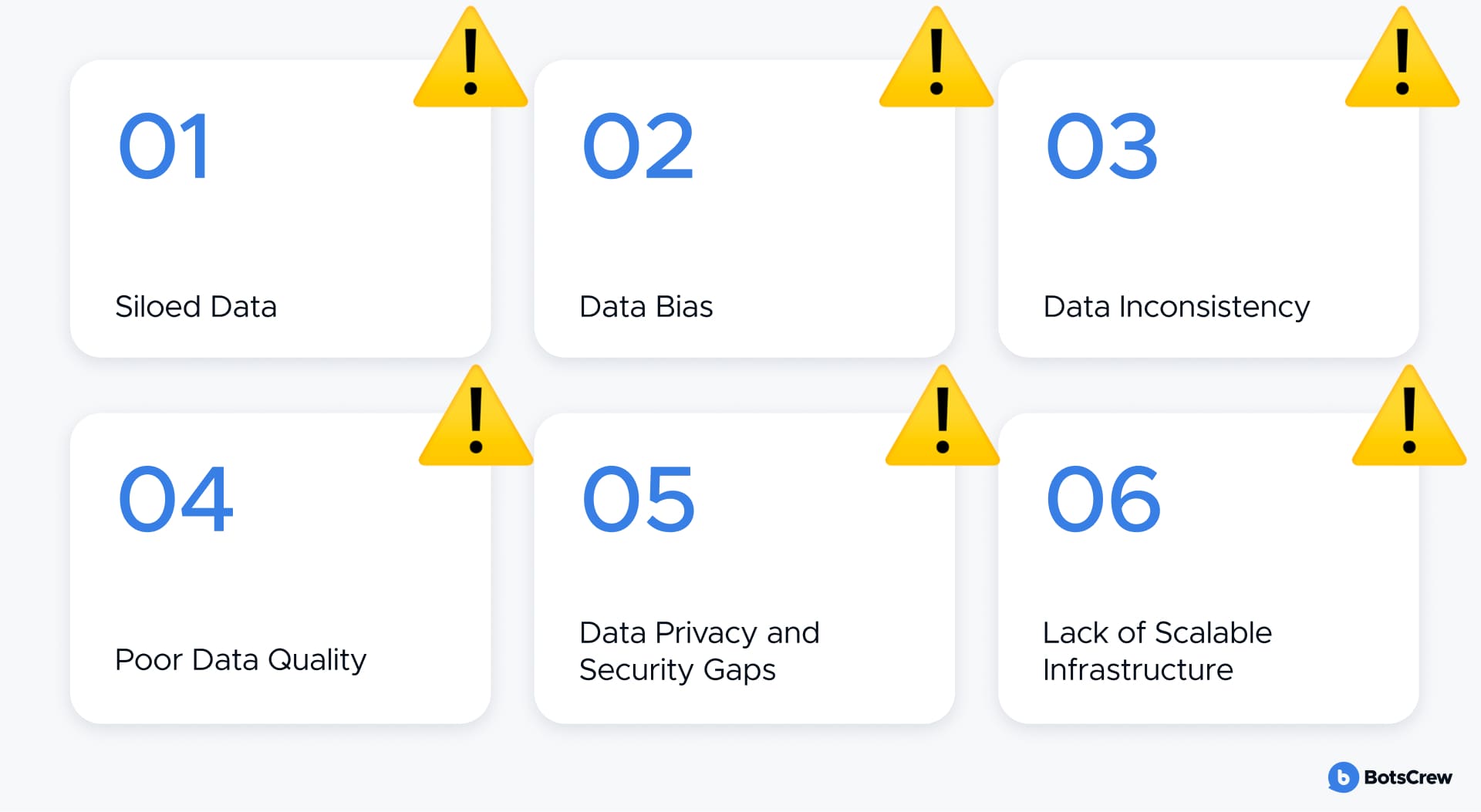
Common Pitfalls That Undermine AI Data Readiness
Too often, organizations rush into AI initiatives without addressing foundational issues that quietly undermine performance. Below are six of the most common — and costly — data pitfalls that can stall progress, introduce risk, and dilute outcomes. Knowing how to fix them is what sets high-performing, AI-ready organizations apart:
Siloed Data
When teams operate in isolation — using different tools, formats, and storage systems — data becomes trapped in departmental silos. And siloed data fragments insight, limits visibility, and starves AI models of the full context they need to identify meaningful patterns.
Data stored in disparate locations, formats, and schemas is a major barrier to AI readiness. A G2 study shows 70% of organizations operate with hybrid cloud storage, and almost 50% use multiple solutions, creating fragmented data environments that AI systems struggle to access.
Example: A retailer's marketing and supply chain teams might track customer demand separately. Without alignment, an AI model forecasting demand may overlook critical campaign data, leading to stockouts or overproduction.
Break down silos with a centralized data architecture, such as a cloud-based data lake or warehouse. Encourage cross-functional data sharing and integration to ensure data is AI-ready across the organization.
Data Bias
AI models reflect the data they are trained on — and if that data is biased, the model will be too. Skewed training data can produce discriminatory outcomes, damage reputations, and trigger regulatory scrutiny.
Example: Amazon had to scrap its AI-driven hiring tool in 2018 after discovering it was favoring male candidates.The model had learned from biased historical data, reinforcing existing inequalities. It was a costly reminder that responsible AI starts with responsible data.
Provide a broad range of patterns and scenarios relevant to your domain. This helps prevent algorithmic bias and improves generalization across different contexts. Audit training data for demographic, regional, and socioeconomic bias. In high-stakes areas like hiring, lending, or healthcare, validate outputs with real-world testing and human oversight.
Data Inconsistency
AI systems — especially those using machine learning (ML) or large language models (LLMs) — need data to be well-structured, accessible, and stored in consistent formats to operate effectively. When data comes in different formats or uses varying terminology, even minor discrepancies can throw AI systems off track. Inconsistent inputs confuse machine learning pipelines and degrade model accuracy.
Example: In healthcare, patient gender may be recorded as “F,” “Female,” or even left blank. This inconsistency can confuse diagnostic models and result in poor patient stratification.
Discover the 3 types of data used in AI:
- Structured: Clearly defined formats like tables and databases (e.g., customer profiles, sales logs).
- Unstructured: Text, audio, video — used in NLP and computer vision tasks.
- Semi-structured: Formats like XML or JSON that include metadata but lack a rigid schema.
Unify structured and semi-structured data in a centralized data warehouse. When using tools like Microsoft Copilot, ensure your data is consolidated in Microsoft 365 to break down silos. If centralization isn't feasible, build robust ETL/ELT pipelines to clean, transform, and normalize data from multiple sources.
Poor Data Quality
Raw data is often riddled with errors, inconsistencies, missing values, duplicates, and irrelevant noise that can significantly reduce model accuracy and usefulness. Inaccurate transactional data, for example, can distort customer behavior analysis, leading to flawed predictions. Dirty data also leads to higher computational costs, delays in model training, and reduced stakeholder trust in AI outcomes.
Example: A fintech company training a fraud detection model on outdated transaction data may miss emerging fraud patterns. Worse, it may falsely flag legitimate transactions, frustrating customers and hurting revenue.
Perform data profiling (EDA) to assess completeness, redundancy, and distribution. Use data quality rules and remediation strategies to deduplicate, merge, and fill gaps. Leverage AI-assisted tools to suggest improvements automatically. Finally, ensure proper data lineage to track changes and understand the origin of training data.
Data Privacy and Security Gaps
AI often relies on PII, financial records, and other confidential data — mishandling it can lead to serious consequences. Data breaches not only erode customer trust but can also result in heavy regulatory penalties. GDPR fines alone reached €1.78 billion in 2023. Poor privacy practices also compromise model fairness and governance.
Example: In 2023, OpenAI temporarily disabled ChatGPT after a bug leaked user chat histories.
Automatically label data based on sensitivity. Employ encryption, secure access controls, and role-based permissions. Use privacy-enhancing technologies like differential privacy and federated learning to train models without exposing sensitive data. Define granular permissions for internal and external access.
Lack of Scalable Infrastructure
Without scalable infrastructure, data preparation becomes a bottleneck. Legacy systems can't keep pace with the volume, velocity, or variety of data modern AI requires. Hitachi Vantara's 2023 survey found that 76% of U.S. companies are concerned their current infrastructure cannot scale to meet upcoming demands, indicating significant infrastructure-related data utilization concerns.
Example: A global logistics firm may collect real-time IoT data from thousands of vehicles, but without a scalable pipeline, they can’t process or use it for predictive maintenance in real time.
Move to cloud-native architectures that support elastic storage and processing. Use MLOps platforms to automate data ingestion, transformation, and model retraining, enabling your AI stack to scale alongside your ambitions.
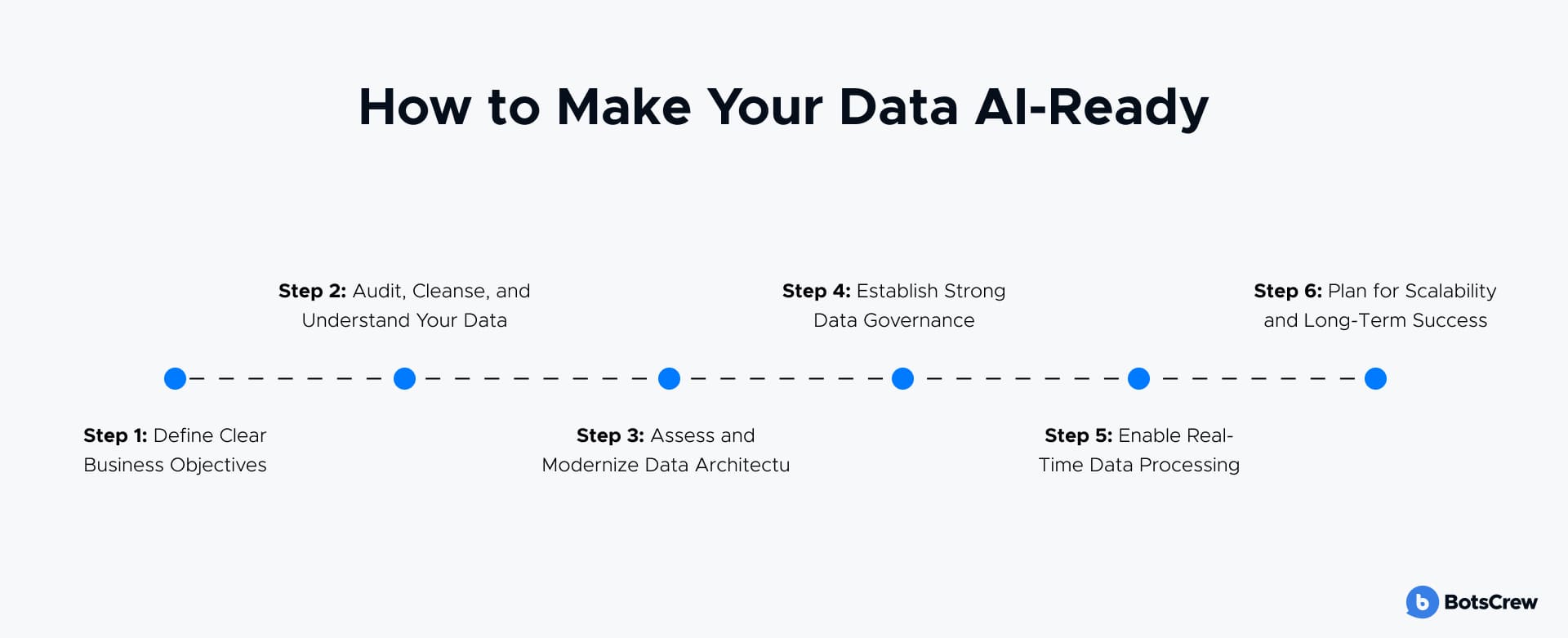
6 Steps to Build an AI-Ready Data Strategy
Here is a step-by-step framework every forward-thinking organization should follow to ensure their data is ready for intelligent automation, analytics, and scalable AI adoption.
🔍 Step 1: Start with the Business — Not the Data
Clarify objectives before shaping the data strategy.
Before involving IT teams or selecting tools, business leaders must define what success looks like. What problems are you trying to solve with AI?
- A retail chain might focus on real-time customer personalization.
- A logistics company may aim to reduce fuel costs through smarter routing.
- A manufacturer could want predictive maintenance to minimize downtime.
These goals will determine:
- What types of data are most relevant (e.g. transactional, behavioral, sensor-based)
- How frequently data needs to be captured (real-time vs batch)
- Which metrics will define success for your AI models.
By aligning your data strategy to business outcomes from the outset, you avoid overinvesting in irrelevant infrastructure or collecting data that delivers no strategic value.
🧹 Step 2: Audit, Clean, and Contextualize Your Data
Dirty data costs more than you think — business leaders say it's one of their top challenges.
Once objectives are defined, it's time to take stock of your current data landscape. This isn't just about volume — it is about quality, accessibility, and readiness for automation.
Key actions:
- Evaluate completeness: Are critical fields missing or outdated?
- Check consistency: Do naming conventions, units, and formats align across systems?
- Identify redundancies: Eliminate duplicate records and obsolete fields.
- Uncover hidden risks: Spot anomalies and outliers that may skew AI outputs.
- Assess freshness: Are you using historical data where real-time inputs are needed?
Automated cleansing tools can drastically speed up this process, but they must be complemented with human oversight to retain context. Documenting the data lineage — where it comes from and how it is transformed — is also essential for transparency and future scalability.
💡 Tip: Even visual tools like histograms, scatter plots, or z-score analysis can help business teams get a better understanding of data quality — even without a data science background.
🧱 Step 3: Modernize Your Data Architecture
Don't force AI to run on systems built for spreadsheets.
Many enterprises still operate on legacy databases and siloed platforms that can't support the volume, velocity, and variety of AI-ready data.
Business-friendly actions to consider:
- Move to the cloud: Cloud-native storage (AWS S3, Azure Blob, Google Cloud Storage) provides scalability, cost-efficiency, and easier integration.
- Adopt hybrid data lakes or lakehouses: These allow storing both structured (e.g. CRM, ERP) and unstructured (emails, PDFs, images) data.
- Ensure system interoperability: AI tools must connect with your ERP, CRM, or proprietary platforms. Middleware or APIs may be needed.
A modern, modular architecture not only supports current AI projects but makes it easier to plug in future capabilities without reengineering your entire data stack.
👩⚖️ Step 4: Implement Strong Data Governance
You can't trust AI if you don't trust the data feeding it.
AI systems are only as ethical and effective as the data they learn from. Without robust data governance, you risk compliance breaches, bias in predictions, or even reputational damage.
Leaders should drive the creation of:
- Ownership models: Assign data stewards across departments to maintain accountability.
- Audit protocols: Use tools to automatically scan datasets for quality, completeness, and duplication.
- Access control and compliance: Define who can access what — and why. Use encryption, role-based access, and logging to meet GDPR, HIPAA, or CCPA standards.
- Bias and fairness monitoring: Regularly evaluate training datasets and model outputs for fairness and unintended bias.
- Data lineage tracking: Use metadata management tools to trace the entire lifecycle of each dataset.
⚡ Step 5: Embrace Real-Time Data Processing
AI doesn't just learn from history — it acts in the moment.
Use cases like fraud detection, predictive maintenance, and dynamic pricing depend on real-time data streams.
To enable real-time insights:
- Use streaming platforms: Kafka, Flink, or Spark Streaming can process data in motion.
- Adopt edge computing: For use cases like IoT or retail, processing at the source (e.g. sensors or cameras) reduces latency.
- Automate pipelines: CI/CD for data — automated data ingestion and transformation pipelines ensure your AI models are always working with fresh inputs.
This infrastructure may seem technical, but its business benefit is clear: timely insights, faster decisions, and more responsive AI systems.
🚀 Step 6: Plan for Scalability and Long-Term Success
AI isn't a one-off project — it is a long-term capability.
A successful AI initiative often grows beyond its initial use case. Leaders must think beyond proof-of-concept and set their organizations up for future scaling.
Strategic enablers:
- MLOps adoption: Treat model development like software engineering. Automate deployment, testing, and monitoring.
- Cross-functional collaboration: Ensure business, data, and IT teams share the same language and KPIs.
- Roadmap design: Outline how AI will expand across departments — start small, but think big.
- Cultural shift: Foster data literacy and AI awareness among employees. Make data-driven decision-making a core business competency.
Whether you are exploring first use cases or scaling enterprise-wide initiatives, success starts with your data. With a clear strategy and the right AI development partner, preparing AI-ready data becomes the foundation for powerful, scalable solutions — be it traditional machine learning, advanced AI, or emerging agentic systems.
At BotsCrew, we help organizations turn fragmented, underutilized data into a strategic advantage — laying the groundwork for AI systems that deliver measurable business impact.
Make your Data AI-Ready!
As the field of AI continues to advance, investing in AI-ready data today means your organization is equipped to adapt, innovate, and lead tomorrow. Whether you are just starting out or scaling existing AI capabilities, building a foundation of high-quality, well-structured data is a move that drives efficiency, sparks innovation, and unlocks a lasting competitive edge.
Ready to unlock the full potential of AI-ready customer data? Discover how BotsCrew can help you generate rich, reliable, and fully AI-ready data that powers smarter decisions and future-proof growth.


