




What Is Semi-Structured Data? Examples, Use Cases, and How to Analyze It
Semi-structured data sits between structured databases and unstructured content, combining flexible formats with meaningful organization. In this guide, we explore what semi-structured data is, how organizations use it, and how it can be analyzed to support modern AI and data-driven systems.

Organizations are generating more data than ever before—from application logs and IoT telemetry to emails, documents, and API responses. However, not all of this data fits neatly into rows and columns.

A significant portion of enterprise data today exists in a middle ground between rigidly structured databases and completely unstructured content. This category is known as semi-structured data, and it plays an increasingly important role in modern analytics and AI systems.
For organizations adopting AI, understanding semi-structured data is critical. Many enterprise AI initiatives—from customer support automation to predictive analytics and large language model (LLM) applications—rely heavily on this type of data.
However, semi-structured data introduces unique challenges. It offers flexibility and richness but requires specialized approaches for storage, processing, and analysis.
This article explores what semi-structured data is, how it differs from other data types, and how organizations can effectively analyze and leverage it for AI-driven decision-making.
Planning an AI initiative? Start with the right data strategy.
Semi-structured data plays a critical role in modern AI architectures—from conversational AI systems to real-time analytics pipelines. However, building reliable AI applications requires the right infrastructure, governance, and integration approach.
What Is Semi-Structured Data?
Semi-structured data refers to data that does not follow a strict relational schema but still contains organizational elements such as tags, keys, or metadata that provide structure.
Unlike traditional structured data stored in relational databases, semi-structured data does not require predefined tables or columns. At the same time, it is more organized and machine-readable than completely unstructured data like images or free-form text.
In practice, semi-structured data often appears in formats such as:
- JSON
- XML
- YAML
- HTML
- Log files
- NoSQL document records
These formats use key-value pairs, tags, or hierarchical structures to represent relationships within the data.
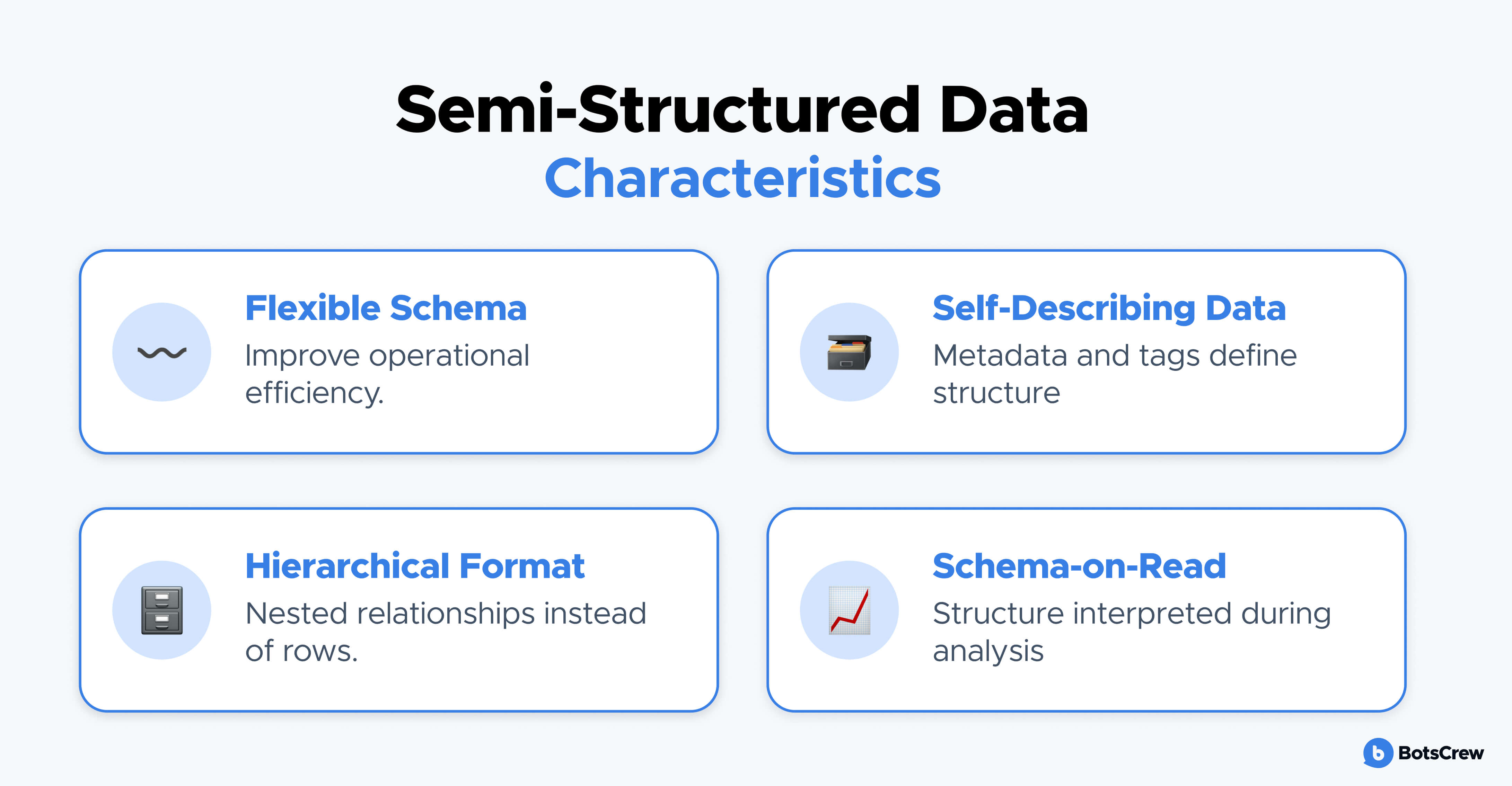
Key Characteristics of semi-structured data
Semi-structured data typically has several defining traits:
- Flexible schema — fields may vary across records
- Self-describing structure through metadata or tags
- Hierarchical organization rather than tabular rows
- Schema-on-read processing, meaning structure is interpreted during analysis rather than enforced at ingestion
This flexibility makes semi-structured data well suited for modern distributed systems and AI pipelines where rigid schemas can become a bottleneck.
Semi-Structured vs. Structured vs. Unstructured Data
To understand the role of semi-structured data in enterprise AI, it helps to compare it with other common data categories.
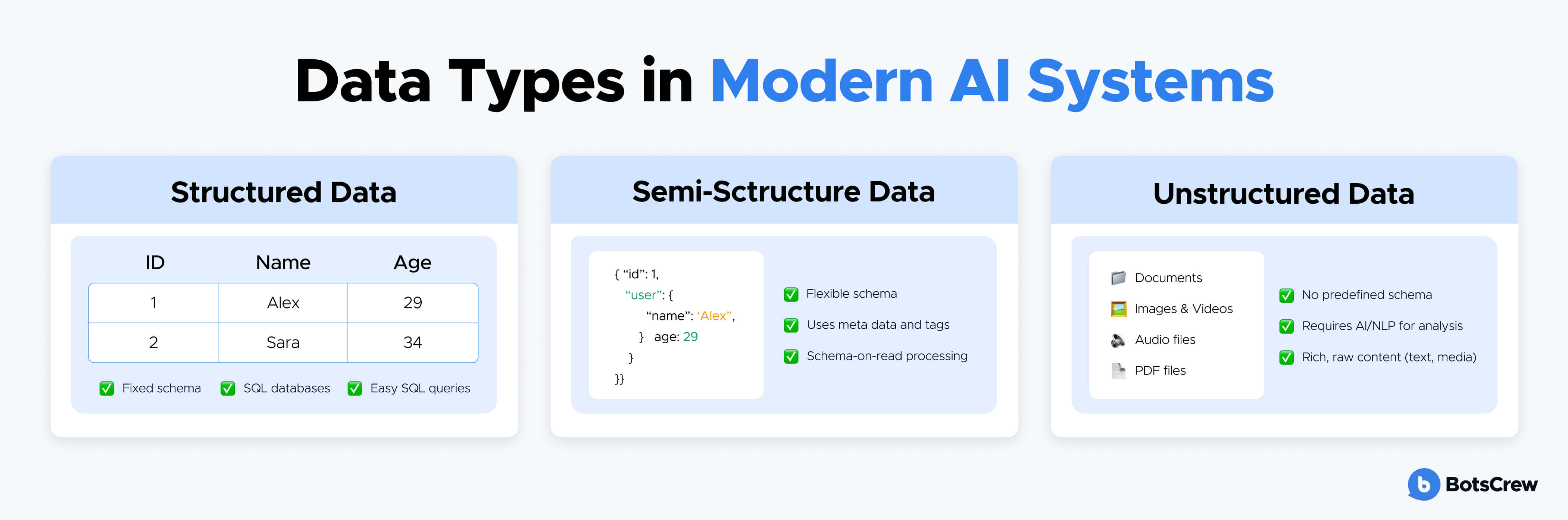
Structured Data
Structured data is highly organized and stored in predefined schemas.
Examples include:
- CRM databases
- Financial transaction tables
- Inventory management systems
- SQL-based relational databases
Characteristics:
- Fixed schema
- Strong data validation
- Easy querying with SQL
- Highly consistent format
While structured data is ideal for traditional analytics, it can struggle to represent complex or evolving data relationships.
Unstructured Data
Unstructured data contains no inherent organizational model.
Examples include:
- Images
- Audio recordings
- Video files
- Free-form text documents
- Social media posts
Analyzing unstructured data typically requires AI techniques such as computer vision, NLP, or speech recognition.
Semi-Structured Data
Semi-structured data sits between these two extremes.
Examples include:
- API responses in JSON
- Webpage HTML
- IoT sensor messages
- Email metadata
- Application logs
It provides enough structure for automated processing while retaining flexibility for evolving data models.
This balance explains why semi-structured data has become a core component of modern data architectures.
Read our guide: Structured vs. Unstructured Data
Want a deeper understanding of how structured and unstructured data differ—and how each impacts AI systems?
Real-World Use Cases of Semi-Structured Data
Semi-structured data plays a critical role across many enterprise systems because it captures dynamic, context-rich information generated by modern digital platforms. Unlike rigid database tables, semi-structured formats allow organizations to collect evolving data without constantly redesigning schemas.
This flexibility makes semi-structured data particularly valuable for AI systems, operational analytics, and large-scale digital infrastructure.
Below are several real-world applications where semi-structured data is commonly used and where it delivers significant business value.
Customer Support and Conversational AI
Customer support environments generate large volumes of semi-structured data across multiple channels, including chatbots, helpdesk systems, and support platforms.
These datasets typically include structured fields such as timestamps and ticket IDs combined with flexible fields like conversation content or issue categories.
Common data sources include:
- Chatbot conversation logs
- Customer support tickets
- CRM event streams
- Knowledge base article metadata
- Email interaction records
Analyzing this data enables organizations to:
- Identify common customer issues and support trends
- Train and improve conversational AI models
- Detect escalation patterns in support workflows
- Optimize knowledge base content
For example, chatbot conversation logs often contain intent tags, timestamps, and contextual messages, making them ideal for training natural language models that improve response accuracy over time.
IoT and Sensor Data Analytics
IoT ecosystems generate continuous streams of semi-structured data from connected devices, machines, and sensors.
Each device may transmit messages with different attributes depending on configuration, firmware version, or operational state. As a result, the data structure often evolves dynamically.
Typical IoT data sources include:
- Device telemetry streams
- Sensor readings and environmental metrics
- Machine health diagnostics
- Equipment status events
- Firmware update notifications
Organizations analyze this data to support use cases such as:
- Predictive maintenance for industrial equipment
- Operational monitoring of infrastructure
- Early detection of equipment anomalies
- Energy optimization in smart facilities
Because IoT systems can produce millions of events per day, semi-structured formats like JSON are commonly used to handle variable data fields efficiently.
Fraud Detection and Security Monitoring
Financial services and digital platforms rely heavily on semi-structured event data to detect suspicious behavior and potential fraud.
Security systems often aggregate signals from multiple systems, including transaction records, user activity logs, and authentication events.
Examples of relevant datasets include:
- Payment transaction metadata
- login attempts and authentication records
- device fingerprints and session data
- API access logs
- network traffic events
AI and machine learning models analyze this information to detect anomalies such as:
- unusual transaction patterns
- suspicious login behavior
- account takeover attempts
- abnormal API activity
Because threat patterns constantly evolve, semi-structured data formats allow organizations to capture new signals without restructuring entire data pipelines.
Product Analytics and User Behavior Tracking
Digital products collect detailed user interaction data to understand how customers engage with applications, websites, and digital services.
User behavior events often contain flexible attributes that vary depending on user actions, device types, or product features.
Examples include:
- clickstream events
- feature usage logs
- mobile app interactions
- search activity data
- session metadata
Analyzing this semi-structured data helps product teams:
- identify popular features
- detect friction in user journeys
- improve onboarding experiences
- personalize product recommendations
For AI-driven products, this data also provides valuable signals for behavioral modeling and personalization algorithms.
AI and LLM Knowledge Systems
Semi-structured data is increasingly important for organizations deploying AI assistants, internal copilots, and LLM-powered knowledge systems.
Many enterprise knowledge assets contain both structured and unstructured elements, making semi-structured formats a natural fit.
Examples of these data sources include:
- document metadata and annotations
- internal wiki structures
- API responses from enterprise systems
- support knowledge base articles
- conversation transcripts with contextual tags
In modern AI architectures, semi-structured data often supports:
- retrieval-augmented generation (RAG)
- knowledge indexing and search
- conversational analytics
- automated document classification
Well-organized semi-structured data improves information retrieval accuracy, which directly impacts the reliability of AI-generated responses.
Supply Chain and Operational Data Integration
Supply chain ecosystems involve data from multiple partners, platforms, and systems, each producing information in different formats.
Semi-structured data is commonly used to exchange and aggregate operational information across systems.
Examples include:
- shipment tracking updates
- logistics event records
- inventory status notifications
- supplier data feeds
- order processing messages
Analyzing this data enables organizations to:
- monitor supply chain performance
- detect delays or disruptions
- improve demand forecasting
- optimize logistics operations
Because supply chain data often changes structure as processes evolve, semi-structured formats provide the flexibility required for large-scale integration across partners and platforms.
Across industries, semi-structured data acts as a critical bridge between operational systems, analytics platforms, and AI models. Organizations that develop effective methods for processing and analyzing this data gain deeper insights into both system behavior and customer interactions—enabling more informed decisions and more reliable AI systems.
Need help designing scalable AI systems?
From conversational AI platforms to enterprise knowledge assistants, successful AI solutions depend on well-designed data pipelines and integration strategies.
Strategic Considerations for AI and Data Leaders
Semi-structured data offers flexibility and scalability, but it also introduces new complexities for organizations building modern data platforms and AI systems. Unlike traditional structured datasets, semi-structured data requires thoughtful architectural decisions and governance frameworks to ensure it remains usable, reliable, and scalable.
For CTOs, data leaders, and AI teams, effectively managing semi-structured data is often a foundational requirement for successful AI implementation. The following strategic considerations can help organizations build a robust approach to handling this type of data.
Establishing Data Governance and Standardization
While semi-structured data provides flexibility, excessive variability can quickly lead to inconsistent datasets that are difficult to analyze.
Organizations should implement governance policies that maintain structure without eliminating flexibility.
Key governance practices include:
- Defining standard naming conventions for data fields
- Establishing event schemas or message templates
- Maintaining clear data documentation and metadata catalogs
- Implementing validation rules for critical attributes
Without governance, semi-structured datasets can accumulate inconsistent formats, making downstream analytics and AI model development significantly more difficult.
A balanced governance approach allows organizations to maintain data flexibility while preserving analytical reliability.
Designing Scalable Data Architectures
Semi-structured data often originates from distributed systems such as microservices, IoT devices, or event-driven platforms. As data volume grows, organizations need infrastructure capable of processing large and continuously evolving datasets.
Modern architectures that support semi-structured data typically include:
- Data lakes or lakehouse architectures for flexible storage
- Stream processing systems for real-time event ingestion
- Distributed processing frameworks for large-scale analytics
- Cloud-native storage solutions optimized for JSON and document-based data
These architectures allow organizations to ingest diverse data sources while maintaining the performance required for analytics and AI workloads.
For enterprises scaling AI initiatives, data infrastructure must support both batch processing and real-time data pipelines.
Managing Data Quality and Consistency
Semi-structured data can contain inconsistencies such as missing fields, unexpected attributes, or inconsistent naming conventions.
If not addressed early, these issues can undermine analytics reliability and degrade machine learning model performance.
AI and data teams should implement processes to monitor and improve data quality, including:
- Automated data validation checks
- Schema evolution monitoring
- Data normalization processes
- Anomaly detection for irregular data patterns
These processes help ensure that semi-structured data remains usable and trustworthy across multiple analytics and AI applications.
Building Efficient Data Transformation Pipelines
Raw semi-structured data often needs to be transformed before it can be used effectively by analytics platforms or machine learning models.
Organizations typically implement transformation pipelines that perform tasks such as:
- Parsing JSON, XML, or log records
- Flattening nested structures
- Extracting relevant attributes
- Standardizing field formats
Efficient transformation pipelines enable organizations to convert raw operational data into structured datasets suitable for analytics, reporting, and machine learning workflows.
Automation is particularly important at scale, as manual data preparation becomes unsustainable when dealing with high-volume event streams.
Supporting AI and Machine Learning Workflows
Many AI systems rely heavily on semi-structured data generated by operational systems, user interactions, or external data sources.
Examples include:
- conversational AI training datasets
- user behavior analytics
- event-driven recommendation systems
- fraud detection models
To support these use cases, organizations must ensure that semi-structured datasets can be easily integrated into machine learning pipelines.
Key capabilities include:
- feature extraction from event logs
- standardized event tracking frameworks
- integration with feature stores
- reproducible data transformation processes
These capabilities help AI teams convert semi-structured operational data into consistent, high-quality features for model training and inference.
Enabling Real-Time Data Processing
Many modern AI applications require near real-time data analysis, particularly in domains such as fraud detection, system monitoring, and personalization.
Semi-structured event streams are often the primary input for these systems.
To support real-time AI capabilities, organizations may implement:
- event streaming platforms
- real-time analytics engines
- stream-based data enrichment pipelines
- event-driven AI inference systems
These architectures allow organizations to detect patterns, anomalies, or opportunities as events occur rather than after batch processing delays.
Preparing Data for LLM and Generative AI Systems
As enterprises adopt generative AI and large language models, semi-structured data is becoming a critical component of knowledge pipelines.
Many enterprise knowledge assets contain a mixture of structured fields and unstructured content, such as:
- document metadata
- tagged conversation transcripts
- knowledge base article structures
- API outputs and operational records
Organizing these datasets effectively enables organizations to build more reliable AI applications, including:
- retrieval-augmented generation (RAG) systems
- enterprise search platforms
- AI-powered support assistants
- internal knowledge copilots
In these systems, semi-structured data often provides the contextual metadata that improves retrieval accuracy and response relevance.
Aligning Data Strategy with Business Objectives
Finally, data leaders should ensure that semi-structured data initiatives are aligned with broader organizational goals.
Rather than collecting data indiscriminately, organizations should focus on datasets that support measurable outcomes.
This may involve prioritizing data collection that supports:
- operational visibility
- improved customer experience
- risk management
- AI-driven automation
By aligning data strategy with business objectives, organizations can ensure that semi-structured data becomes a strategic asset rather than an unmanaged data source.
Conclusion
Semi-structured data has become a fundamental component of modern data ecosystems. It bridges the gap between rigid relational databases and completely unstructured information, enabling organizations to capture the dynamic data generated by digital platforms, connected devices, and AI-powered applications.
For enterprises adopting AI, this type of data often represents a critical source of operational insight and model input. From customer support logs and product interaction events to IoT telemetry and API outputs, semi-structured data fuels many of the analytics and machine learning systems that power intelligent products and services.
However, realizing its full value requires more than simply collecting the data. Organizations must implement the right data architectures, governance frameworks, and processing pipelines to transform semi-structured information into reliable, usable assets for analytics and AI.
Companies that invest in scalable data pipelines, strong data governance, and AI-ready infrastructure are better positioned to:
- improve operational visibility
- build more reliable AI models
- enable real-time decision-making
- accelerate enterprise AI adoption
For many organizations, designing and implementing these systems requires deep expertise in data engineering, AI architecture, and intelligent automation.
At BotsCrew, we help organizations transform complex data environments into scalable AI solutions. Our team works with enterprises to design AI strategies, build conversational AI systems, and develop data-driven applications that integrate seamlessly with existing platforms and data ecosystems.
Whether you are exploring AI opportunities or scaling existing initiatives, partnering with experienced AI consultants can significantly accelerate implementation and reduce technical risk.
If your organization is looking to unlock the value of its data and build reliable AI systems, the BotsCrew team can help you design and implement solutions tailored to your business goals.
Transform your data into intelligent applications.
Organizations across industries are using semi-structured data to power automation, analytics, and AI-driven decision-making. But turning raw data into production-ready AI systems requires specialized expertise.


