




Enterprise AI Guardrails: Safety Techniques for Production Systems
Your AI just went to production. Now what? Keeping an AI system safe, reliable, and aligned with your business — at scale, under pressure, with real users — is where most enterprises find the real surprises. We've compiled an AI guardrails guide for systems that can't afford to fail.


Every week, another enterprise pilot makes the jump to production — and another one doesn't make the headlines, quietly shelved after a governance audit or a high-profile model failure that escaped into the wild.
Why? Nine times out of ten, it's not the model that fails — it is the infrastructure surrounding it. The AI guardrails that define what the system can say, what it cannot access, and who is ultimately accountable when something goes wrong.
For C-suite leaders, the question now is whether your organization has the architecture, governance framework, and technical depth to deploy AI without exposing the business to reputational, regulatory, or operational risk. This longread cuts through the noise to give you a precise understanding of what enterprise AI guardrails are and what responsible AI deployment looks like at scale.
What Are AI Guardrails?
LLM guardrails are a set of technical controls, policy rules, and monitoring systems placed around a large language model in production. They act as a governance layer between raw model capability and real-world output, intercepting inputs before they reach the model and screening outputs before they reach your customers or employees.
Source: BotsCrew
Why LLM Guardrails Are a Board-Level Issue Now
Average global cost of a data breach in 2024, according to IBM's annual research.
— a figure that escalates significantly when AI systems are implicated, due to the scale at which a misconfigured model can exfiltrate or generate harmful content before detection.
The Regulatory Landscape Has Changed Permanently
The EU AI Act classifies many enterprise AI use cases as high-risk, requiring mandatory conformity assessments, human oversight mechanisms, and detailed technical documentation. GDPR enforcement actions involving AI systems have compounded exposure. In the United States, the FTC, SEC, and sector-specific regulators are all actively issuing guidance on AI deployment practices.
Today AI governance carries legal weight. The EU AI Act imposes penalties of up to €35 million for violations of high-risk systems. The SEC expects material AI risks disclosed in public filings. State attorneys general are rapidly building enforcement capacity. For Fortune 500 leadership, the question has shifted — not whether to implement a governance framework, but whether the one already in place will hold up under scrutiny.
The Hidden Risk: Prompt Injection and Adversarial Inputs
Beyond compliance, there is a technical threat that receives insufficient attention in C-suite conversations: AI prompt injection prevention. Unlike traditional cybersecurity exploits that target code vulnerabilities, prompt injection attacks exploit the linguistic flexibility that makes LLMs valuable in the first place.
An attacker — or even a well-meaning but sophisticated user — can craft inputs designed to override the model's system instructions, extract information from its context window, impersonate authorized users, or manipulate it into producing outputs that violate your policies. In an enterprise deployment connected to internal knowledge bases, CRM systems, or financial data via retrieval-augmented generation (RAG), the potential impact of a successful injection attack is not theoretical. It is a data incident.
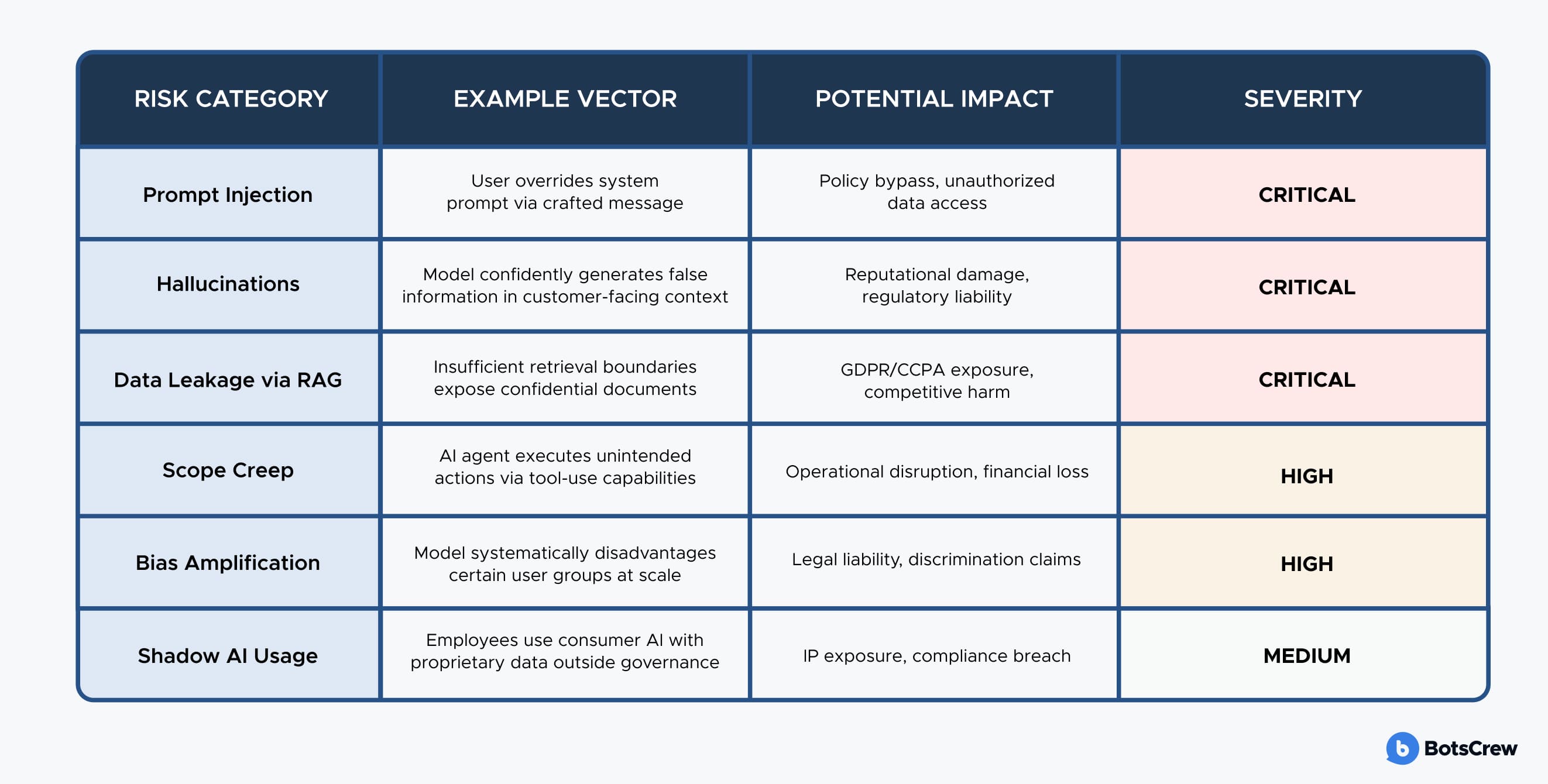
Core Safety Techniques for Production AI Systems
The following techniques represent the current state of responsible AI deployment for enterprise production systems. These are not academic proposals, but battle-tested approaches deployed across systems serving millions of users.
1. Layered Input Validation and Sanitization
Before any user input reaches your LLM, it should pass through a validation pipeline. This includes pattern-matching against known injection signatures, semantic classifiers trained to detect adversarial framing, and PII detection routines that strip or pseudonymize personal data before it enters the model's context window. In regulated industries such as healthcare and financial services, this is not optional.
The sophistication required here scales with your threat model. A simple content classification layer may suffice for an internal productivity assistant. A customer-facing agent connected to account data requires defense-in-depth: multiple independent classifiers operating in sequence, with fail-safe defaults that surface human escalation paths when confidence is low.
2. Retrieval-Augmented Generation with Access Controls
RAG has become the dominant architecture for enterprise AI deployments because it allows models to ground responses in proprietary knowledge without requiring expensive fine-tuning cycles. However, RAG introduces its governance requirements. Every document, database, or knowledge source in your retrieval corpus needs document-level access control that mirrors your existing permission model.
A sales representative should be able to ask the AI about product specifications, but not retrieve confidential pricing strategies or board-level communications. Implementing this requires treating your retrieval layer as an authenticated service, not a simple search index, validating user identity and role at query time, not just at login.
Source: BotsCrew
3. Structured Output Enforcement
For AI agents that take actions such as filling forms, triggering API calls, generating documents — structured output enforcement is essential. Rather than parsing free-text model responses and hoping they conform to expected formats, modern deployments use constrained decoding or output schema validation to ensure the model can only produce structurally valid responses. This dramatically reduces the attack surface for injection-driven misbehavior and eliminates an entire class of integration bugs.
4. Real-Time Output Monitoring and Anomaly Detection
Even a well-designed system will encounter edge cases that no static ruleset anticipated. Real-time output monitoring — using a combination of rule-based classifiers and secondary AI models trained for policy adherence — creates a dynamic detection layer that improves over time.
Anomaly detection pipelines can surface unusual patterns: a spike in policy violations from a specific user segment, an unexpected topic cluster emerging in customer queries, or output characteristics that suggest the underlying model has drifted from baseline behavior.
Want to understand your current compliance exposure?
Book a free 30-minute consultation — we'll map your gaps against the EU AI Act, GDPR, and HIPAA requirements.
AI Governance for Enterprise: Beyond the Technical Layer
Responsible AI deployment requires an organizational governance structure that assigns accountability, defines escalation pathways, and establishes feedback loops that enable your AI systems to improve with use rather than degrade.
Defining the AI Governance Stack
Enterprise AI governance operates at three levels simultaneously. At the strategic level, the board and C-suite define the organization's AI risk appetite, approve high-risk deployments, and own the relationship with regulators.
At the operational level, cross-functional committees — typically including Legal, Compliance, IT Security, and the relevant business unit — review deployment proposals and monitor ongoing performance against defined KPIs. At the technical level, engineering teams implement controls and maintain audit trails that enable strategic and operational oversight.
Organizations that attempt to implement AI governance without all three levels aligned will find that technical controls are routinely circumvented by business pressure, or that technically sound systems operate outside defined risk appetite because the strategic layer never articulated it clearly.
The AI Governance Maturity Model
01 Reactive
Ad hoc responses to AI incidents
No formal policy. AI guardrails implemented after incidents occur. Governance owned by IT, not leadership. Most organizations underestimate that they are here.
02 Defined
Policy frameworks exist, but enforcement is inconsistent
AI use documented policies. Basic output filtering in place. Risk assessments conducted pre-deployment but not continuously. Shadow AI usage is a known concern.
03 Managed
Consistent controls across production deployments
Multi-layer technical guardrails. Cross-functional governance committee active. Audit trails maintained. Regulatory compliance documented. Incident response plans tested.
04 Optimizing
Governance creates competitive advantage
Continuous monitoring with anomaly detection. Governance integrated into the product development lifecycle. AI risk appetite formally defined by the board. Trusted by regulators, customers, and partners.
The transition from Level 2 to Level 3 is where most Fortune 500 organizations are struggling right now. The gap is mostly a lack of technical implementation depth and cross-functional coordination. Closing it typically requires external expertise with a track record of doing exactly this in high-stakes environments.
What Responsible Deployment Actually Looks Like
The majority of enterprise AI pilots succeed. The majority of enterprise AI production deployments underperform. The gap is almost always in the transition: moving from a controlled demo environment to a system handling real users, edge cases, and adversarial inputs at scale.
Based on over 10 years of AI development experience and over 200 successful enterprise deployments — including work with Fortune 500 companies across healthcare, retail, financial services, and manufacturing — the production readiness checklist for responsible AI deployment looks like this:
✅ Red team testing before launch. Dedicated adversarial testing by engineers who are specifically trying to break the system. Injection attempts, jailbreak scenarios, edge case inputs from representative user populations.
✅ Staged rollout with monitoring gates. Launch to 5% of traffic with full telemetry active, establish baseline metrics, and expand only when safety and quality KPIs are met. Never launch to 100% on day one.
✅ Documented incident response plan. What happens when the system produces a policy-violating output? Who is notified? What is the rollback procedure? How is the affected user communicated with? These answers need to be in place before you go live.
✅ Compliance documentation for regulators. A documented record of the technical controls in place, the risk assessment conducted, and the ongoing monitoring regime — formatted for the regulatory audience relevant to your industry.
✅ SLA commitments with defined remediation timelines. Production AI systems require the same SLA rigor as any mission-critical infrastructure. Response times for policy violations, uptime commitments, and model performance degradation thresholds should all be defined in the contract.
✅ Ongoing model performance evaluation. Models drift, user behavior evolves, and new attack vectors emerge. A quarterly evaluation cadence — at minimum — comparing current performance against launch baselines is non-negotiable for systems that matter.
What to Ask Your AI Vendor
If you are evaluating AI development partners, the following questions will separate genuine enterprise capability from polished demo capability:
Source: BotsCrew
Partners who answer these questions with specifics drawn from real deployments are the ones worth engaging. Not sure where to start? Here is a curated list of AI vendors with the deployment experience to back their claims.


