




Retrieval-Augmented Generation Explained for CTOs: Behind Most Reliable AI
Training data has a cutoff, and every enterprise AI deployment eventually hits this wall. Retrieval-Augmented Generation (RAG) solves this by linking the model to a live, queryable knowledge base, so it can rely on real-time information instead of static training alone.


Every enterprise AI project eventually runs into the same frustrating wall: LLMs start hallucinating the moment they run out of knowledge. And they constantly run out of it, leaving teams frustrated and business-critical decisions at risk.
If you've been searching for retrieval-augmented generation explained in plain terms — you are in the right place. RAG was built specifically to break down this wall, and it has quietly become the go-to architecture for production AI in regulated, data-heavy industries.
Retrieval-Augmented Generation Explained: What Is RAG?
What is RAG in large language models? Retrieval-Augmented Generation is a compound AI architecture that combines a retrieval system — typically a vector database or a hybrid search engine — with a generative language model.
Rather than relying solely on the information stored in its training weights, the model gains access to an external knowledge base at inference time. When a query arrives, relevant documents are retrieved and injected into the model's context window, providing grounded material for generating answers that are factually anchored.
Modern RAG pipelines often go further, incorporating multi-stage retrievers, re-rankers, query-reformulation agents, structured knowledge graphs, and advanced evaluation frameworks to ensure accuracy and reliability.
📌 The primary objective of RAG for enterprise AI is to make language models grounded, auditable, and safe enough to deploy against business data without catastrophic hallucination risk.
A traditional fine-tuned model stores knowledge statically — you have to retrain or fine-tune it every time the world changes. RAG flips this approach by externalizing knowledge, turning it into a queryable, continuously updatable resource. This shift has significant operational implications, meaning:
→ you can update the knowledge base without touching the model, version and audit every retrieval
→ trace every generated claim back to a source document
→ comply with data-residency requirements by keeping sensitive documents on-premise while the model runs in the cloud.
How Do RAG Models Work — and How Does RAG Differ from Traditional AI Models?
To understand how RAG works in AI models, it helps to start with what traditional models cannot do. Traditional large language models (LLMs) — fine-tuned or few-shot prompted (i.e., giving the model a few examples in the prompt to guide its response) — operate from a closed book. Every fact they produce is a reconstruction from training data compressed into billions of parameters. This creates several structural problems for enterprise deployments:
#1. Knowledge staleness: training is expensive, so models are retrained infrequently, leaving weeks or months of lag between real-world events and model knowledge.
#2. Hallucination under uncertainty: when a model lacks reliable information for a query, it can produce plausible-sounding but entirely fabricated answers — a behavior that is especially dangerous in legal, medical, or financial contexts.
#3. Opacity: there is no mechanism to ask a fine-tuned model where it learned a particular fact, which makes compliance and audit nearly impossible.
RAG AI models tackle all three challenges. The knowledge base is continuously updated, independent of the model itself. Retrieved documents act as a constraint: the model generates answers within the bounds of what was returned, and if nothing relevant is found, it can simply indicate that. Each response can also be traced back to specific document chunks — with line-level provenance if the system is properly instrumented.
Ready to build a production RAG system?
We'll scope your architecture, challenge your assumptions, and tell you what will actually break in production — in one call.
The Anatomy of a RAG System: Retrieval-Augmented Generation Components
If you are wondering what is RAG architecture, here's the short version: it's a pipeline that connects a language model to an external knowledge store at inference time, swapping out the model's unreliable memory for retrievable, auditable facts. A production RAG pipeline typically consists of five major subsystems.
1 · DOCUMENT INGESTION & PREPROCESSING
Before retrieval can happen, documents must be loaded, cleaned, and normalised. Enterprise document estates are messy by nature: PDFs with multi-column layouts, Excel sheets with embedded formulas, HTML pages with navigation noise, scanned images that require OCR, emails with thread histories interleaved, SharePoint wikis with broken internal links. Your ingestion layer must handle all of these with high fidelity.
The key tasks at this stage are:
✅ extracting clean UTF-8 text from binary formats (taking files like PDFs, Word docs, images, etc. and converting them into clean, readable text that a system can process)
✅ removing repetitive boilerplate content — like headers, footers, cookie banners, and legal disclaimers that appear in every document
✅ detecting and preserving document structure (headings, tables, code blocks, captions)
✅ applying metadata — source URL, author, creation date, document type, access control labels — that will later power filtered retrieval
✅ routing documents to specialised parsers when format-specific logic is needed.
2 · CHUNKING: THE MOST CONSEQUENTIAL DECISION YOU WILL MAKE
Chunking is the process of breaking documents into segments small enough to fit into a model's context window, leaving space for the query and generated response.
Smaller chunks improve retrieval precision, often returning exactly the sentence that answers the question, but they sacrifice context — the model may miss surrounding information that gives the answer meaning.
Larger chunks preserve context, but retrieval quality can suffer, as relevant signals get diluted by surrounding, irrelevant text.
📌 There is no universally optimal chunk size. The right choice depends on the nature of your documents, your queries, the optimal input length of your embedding model, and the context window of your generation model. Most teams allocate between 256 and 1,024 tokens to the retrieval unit, with a larger chunk passed to the LLM for generation.
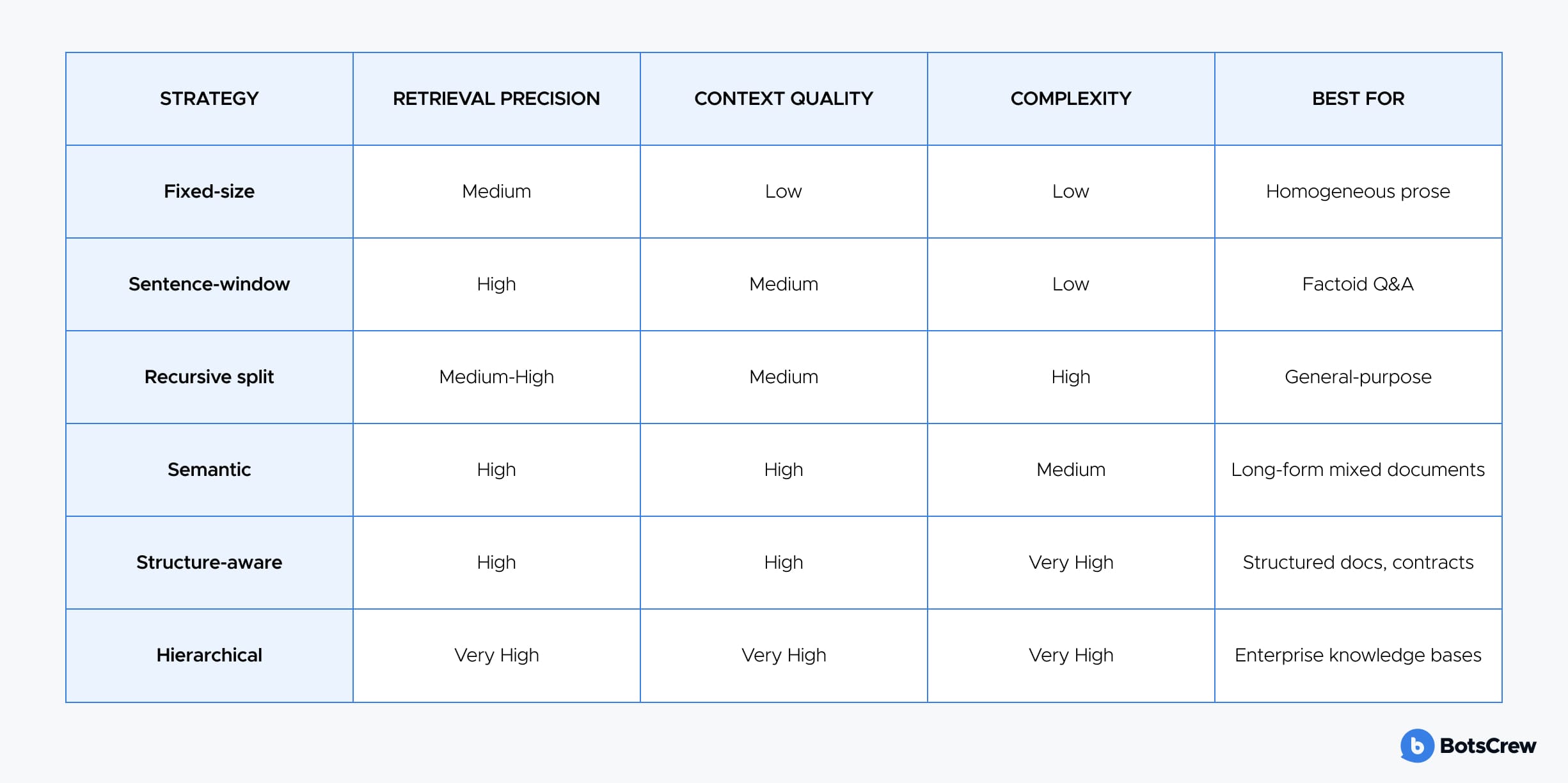
The most commonly deployed RAG chunking strategies are as follows:
Fixed-size chunking is the simplest: you split by token or character count, usually with a small overlap. It's fast and predictable, but it doesn't understand the meaning — sentences can get cut in half, and table headers might end up separated from their rows. Works best for plain, prose-heavy documents.
Sentence-window chunking embeds at the sentence level and keeps a few surrounding sentences together. This gives precise answers while preserving enough context to make them meaningful — perfect for fact-based questions in dense reference materials.
Recursive character splitting (LangChain's default) tries to split at natural language boundaries: paragraphs first, then sentences, words, and finally characters if needed. This method is more careful than fixed-size chunking and works well for mixed or semi-structured documents.
Semantic chunking takes things a step further: it looks at the meaning of sentences and splits when a topic changes. While more computationally intensive, it produces chunks that make sense on their own — ideal for long, varied documents like annual reports or research papers.
Structure-aware chunking leverages the document's built-in structure — headings, lists, tables — to create natural, coherent chunks. It requires a good parser upstream, but it shines for highly structured content like legal contracts, technical manuals, or API documentation.
Hierarchical chunking organizes content at multiple levels — from full document summaries to section summaries to fine-grained paragraphs. Queries can be routed intelligently: coarse chunks give context, while fine chunks provide precise answers. This approach works especially well for complex knowledge bases.
3 · EMBEDDING MODELS
Chunks are transformed into dense vector representations using an embedding model. The quality of these vectors directly impacts retrieval performance, because the system ultimately relies on a nearest-neighbor search in this vector space.
Ideally, queries that are semantically similar to stored chunks appear close together, while unrelated queries remain far apart.
Critical considerations when selecting an embedding model:
🤔 Maximum input length (some RAG models in AI saturate at 512 tokens, making them incompatible with larger chunks).
🤔 Domain specificity (general embedding models underperform on highly technical vocabulary — biomedical, legal, financial — where domain-adapted models like PubMedBERT embeddings or FinBERT-derived encoders are superior).
🤔 The asymmetry between query and document encoding (bi-encoder RAG models in AI encode queries and documents independently and are fast but slightly less accurate; cross-encoder models attend jointly across query and document and are highly accurate but prohibitively slow for first-stage retrieval).
Not sure if you need RAG, fine-tuning, or both?
The wrong architecture choice can cost 3–6 months and $200K+ in rework. This blog post walks C-level leaders through a practical decision framework — the right questions to ask before committing.
4 · THE VECTOR STORE & RETRIEVAL LAYER
Once chunks are embedded, they're stored in a vector database capable of performing approximate nearest-neighbor (ANN) searches at scale. Common algorithms include HNSW (Hierarchical Navigable Small World graphs), which offers an excellent balance between query speed and recall; IVF-PQ (Inverted File with Product Quantization), which is more memory-efficient for very large datasets; and ScaNN, Google's highly optimized solution for large-scale production deployments.
Choosing the right ANN algorithm is critical for ensuring fast, accurate retrieval in enterprise applications where both speed and reliability matter.
The vector store landscape includes:
- Pinecone (fully managed, strong performance, opinionated API)
- Weaviate (hybrid search built-in, strong graph capabilities, open-source with managed cloud)
- Qdrant (Rust-native, excellent performance per dollar, advanced filtering)
- Milvus (enterprise-grade, cloud-native architecture, strong scaling story)
- pgvector (PostgreSQL extension — the pragmatic choice when you already have Postgres and want to avoid adding another stateful service).
At query time, the process starts by embedding the query and running an ANN search against the indexed chunks. Metadata filters can then be applied to narrow results — for instance, limiting documents to a specific date range, author, product line, or only those the requesting user is authorized to access. In enterprise RAG deployments, metadata filtering isn't optional: without it, the system could return documents a user shouldn't see, creating a serious compliance risk.
5 · RE-RANKING
First-stage retrieval using ANN search is fast but not always precise. It returns the top-k chunks based on vector similarity, but for complex queries, similarity in vector space does not always match true relevance. That's where a re-ranker comes in.
Using a cross-encoder architecture, it jointly considers the query and each retrieved candidate, producing relevance scores that are far more semantically accurate than simple cosine similarity. Incorporating a re-ranker into a RAG pipeline typically improves answer quality by 10–30%, while adding only a modest latency of 50–200 milliseconds in most implementations.
RAG for Enterprise AI: Architectural Considerations for CTOs
If you are a technical leader deciding whether and how to adopt RAG, the architecture decision is inseparable from your operational, compliance, and cost constraints. Here is how to think about the major decision axes.
BUILD VS. BUY
The managed RAG landscape has matured significantly. Platforms like Azure AI Search, AWS Bedrock Knowledge Bases, Google Vertex AI Search, and Cohere's Coral now provide production-ready managed RAG with varying levels of customization. These solutions are a strong fit when your document estate is relatively standard — think English-language PDFs and web content — your queries are general-purpose, and your team lacks the bandwidth to build and tune a custom stack.
On the other hand, a custom-built stack using open-source components — such as LlamaIndex or LangChain for orchestration, Qdrant or Milvus for vector storage, open embedding models, and vLLM for inference — is ideal when you need precise control over chunking, access policies, cost optimization, or on-premise deployment. Keep in mind that engineering a production-ready custom stack is non-trivial: expect 3–6 months to implement a fully hardened system with proper evaluation infrastructure.
Evaluating a custom RAG stack?
Talk to our engineers about what a production-ready build actually costs for your use case.
ON-PREMISE VS. CLOUD
Regulated industries — including banking, healthcare, defense, and legal — often face strict data residency or sovereignty requirements, making cloud-based embeddings and generation impractical. As a result, these organizations are increasingly turning to on-premises or private-cloud architectures, leveraging open-source LLMs such as Llama-3, Mistral, or Qwen, served via vLLM, alongside open embedding models and self-hosted vector stores.
For RAG applications, the performance gap between open-source and cutting-edge models has narrowed considerably: retrieval context provides the bulk of the signal, making on-premises deployments a practical and increasingly attractive option.
KNOWLEDGE BASE ARCHITECTURE
Enterprise knowledge is rarely a single, uniform corpus. Instead, organizations often manage multiple knowledge bases with differing update frequencies, access policies, and query patterns.
For example, product documentation might be updated weekly and queried by customers and support teams, regulatory intelligence could be updated daily and restricted to compliance teams, internal policies might be updated monthly and accessible to all employees, and historical contracts are largely static and queried by legal teams. Each of these corpora typically requires its own index, tailored chunking strategy, embedding model, and access control policy.
LATENCY BUDGET
End-to-end RAG latency for a user-facing application has roughly four components:
- embedding the query (10–50ms with a fast model)
- vector search (5–50ms for well-indexed collections under 10M chunks)
- re-ranking (50–200ms)
- LLM generation (500ms–3s depending on model and response length).
Total P95 latency for a well-optimised RAG pipeline serving a chat interface lands around 1.5–4 seconds, which is acceptable for most enterprise applications. Agentic RAG for enterprise AI with multiple retrieval iterations can reach 10–20 seconds for complex queries, which requires explicit UX treatment — progress indicators, streaming partial responses, or asynchronous task queuing.
For most enterprise AI deployments, it is best to start with a hybrid retrieval architecture combining dense vectors and BM25, use sentence-window chunking by default, rely on a strong commercial embedding model, and implement RAGAS-based evaluation from day one.
Agentic retrieval loops should only be introduced once your evaluation data shows that single-pass retrieval is failing on a meaningful portion of production queries. Complexity in agentic systems compounds quickly — don't add it without clear evidence that it is needed.
Talk to an expert. For free.
Bring your architecture, docs, or evaluations — we'll pinpoint gaps and show what to fix. Chunking, indexing, build vs. buy, costs, and evaluation — straight answers, real clarity.


